We've Moved to the AWS Docs! 🚀
This content has been updated and relocated to improve your experience. Please visit our new site for the latest version: AWS EKS Best Practices Guide on the AWS Docs
Bookmarks and links will continue to work, but we recommend updating them for faster access in the future.
Kubernetes Cluster Autoscaler¶
Overview¶
The Kubernetes Cluster Autoscaler is a popular Cluster Autoscaling solution maintained by SIG Autoscaling. It is responsible for ensuring that your cluster has enough nodes to schedule your pods without wasting resources. It watches for pods that fail to schedule and for nodes that are underutilized. It then simulates the addition or removal of nodes before applying the change to your cluster. The AWS Cloud Provider implementation within Cluster Autoscaler controls the .DesiredReplicas field of your EC2 Auto Scaling Groups.
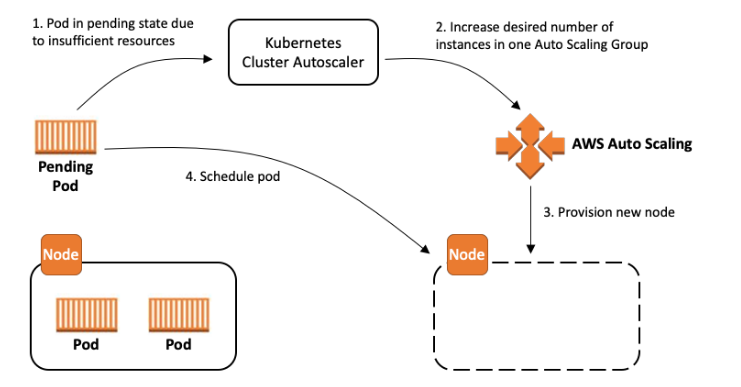
This guide will provide a mental model for configuring the Cluster Autoscaler and choosing the best set of tradeoffs to meet your organization's requirements. While there is no single best configuration, there are a set of configuration options that enable you to trade off performance, scalability, cost, and availability. Additionally, this guide will provide tips and best practices for optimizing your configuration for AWS.
Glossary¶
The following terminology will be used frequently throughout this document. These terms can have broad meaning, but are limited to the definitions below for the purposes of this document.
Scalability refers to how well the Cluster Autoscaler performs as your Kubernetes Cluster increases in number of pods and nodes. As scalability limits are reached, the Cluster Autoscaler's performance and functionality degrades. As the Cluster Autoscaler exceeds its scalability limits, it may no longer add or remove nodes in your cluster.
Performance refers to how quickly the Cluster Autoscaler is able to make and execute scaling decisions. A perfectly performing Cluster Autoscaler would instantly make a decision and trigger a scaling action in response to stimuli, such as a pod becoming unschedulable.
Availability means that pods can be scheduled quickly and without disruption. This includes when newly created pods need to be scheduled and when a scaled down node terminates any remaining pods scheduled to it.
Cost is determined by the decision behind scale out and scale in events. Resources are wasted if an existing node is underutilized or a new node is added that is too large for incoming pods. Depending on the use case, there can be costs associated with prematurely terminating pods due to an aggressive scale down decision.
Node Groups are an abstract Kubernetes concept for a group of nodes within a cluster. It is not a true Kubernetes resource, but exists as an abstraction in the Cluster Autoscaler, Cluster API, and other components. Nodes within a Node Group share properties like labels and taints, but may consist of multiple Availability Zones or Instance Types.
EC2 Auto Scaling Groups can be used as an implementation of Node Groups on EC2. EC2 Auto Scaling Groups are configured to launch instances that automatically join their Kubernetes Clusters and apply labels and taints to their corresponding Node resource in the Kubernetes API.
EC2 Managed Node Groups are another implementation of Node Groups on EC2. They abstract away the complexity manually configuring EC2 Autoscaling Scaling Groups and provide additional management features like node version upgrade and graceful node termination.
Operating the Cluster Autoscaler¶
The Cluster Autoscaler is typically installed as a Deployment in your cluster. It uses leader election to ensure high availability, but work is done by a single replica at a time. It is not horizontally scalable. For basic setups, the default it should work out of the box using the provided installation instructions, but there are a few things to keep in mind.
Ensure that:
- The Cluster Autoscaler's version matches the Cluster's Version. Cross version compatibility is not tested or supported.
- Auto Discovery is enabled, unless you have specific advanced use cases that prevent use of this mode.
Employ least privileged access to the IAM role¶
When the Auto Discovery is used, we strongly recommend that you employ least privilege access by limiting Actions autoscaling:SetDesiredCapacity and autoscaling:TerminateInstanceInAutoScalingGroup to the Auto Scaling groups that are scoped to the current cluster.
This will prevents a Cluster Autoscaler running in one cluster from modifying nodegroups in a different cluster even if the --node-group-auto-discovery argument wasn't scoped down to the nodegroups of the cluster using tags (for example k8s.io/cluster-autoscaler/<cluster-name>).
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"aws:ResourceTag/k8s.io/cluster-autoscaler/enabled": "true",
"aws:ResourceTag/k8s.io/cluster-autoscaler/<my-cluster>": "owned"
}
}
},
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeScalingActivities",
"autoscaling:DescribeTags",
"ec2:DescribeImages",
"ec2:DescribeInstanceTypes",
"ec2:DescribeLaunchTemplateVersions",
"ec2:GetInstanceTypesFromInstanceRequirements",
"eks:DescribeNodegroup"
],
"Resource": "*"
}
]
}
Configuring your Node Groups¶
Effective autoscaling starts with correctly configuring a set of Node Groups for your cluster. Selecting the right set of Node Groups is key to maximizing availability and reducing cost across your workloads. AWS implements Node Groups using EC2 Auto Scaling Groups, which are flexible to a large number of use cases. However, the Cluster Autoscaler makes some assumptions about your Node Groups. Keeping your EC2 Auto Scaling Group configurations consistent with these assumptions will minimize undesired behavior.
Ensure that:
- Each Node in a Node Group has identical scheduling properties, such as Labels, Taints, and Resources.
- For MixedInstancePolicies, the Instance Types must be of the same shape for CPU, Memory, and GPU
- The first Instance Type specified in the policy will be used to simulate scheduling.
- If your policy has additional Instance Types with more resources, resources may be wasted after scale out.
- If your policy has additional Instance Types with less resources, pods may fail to schedule on the instances.
- Node Groups with many nodes are preferred over many Node Groups with fewer nodes. This will have the biggest impact on scalability.
- Wherever possible, prefer EC2 features when both systems provide support (e.g. Regions, MixedInstancePolicy)
Note: We recommend using EKS Managed Node Groups. Managed Node Groups come with powerful management features, including features for Cluster Autoscaler like automatic EC2 Auto Scaling Group discovery and graceful node termination.
Optimizing for Performance and Scalability¶
Understanding the autoscaling algorithm's runtime complexity will help you tune the Cluster Autoscaler to continue operating smoothly in large clusters with greater than 1,000 nodes.
The primary knobs for tuning scalability of the Cluster Autoscaler are the resources provided to the process, the scan interval of the algorithm, and the number of Node Groups in the cluster. There are other factors involved in the true runtime complexity of this algorithm, such as scheduling plugin complexity and number of pods. These are considered to be unconfigurable parameters as they are natural to the cluster's workload and cannot easily be tuned.
The Cluster Autoscaler loads the entire cluster's state into memory, including Pods, Nodes, and Node Groups. On each scan interval, the algorithm identifies unschedulable pods and simulates scheduling for each Node Group. Tuning these factors come with different tradeoffs which should be carefully considered for your use case.
Vertically Autoscaling the Cluster Autoscaler¶
The simplest way to scale the Cluster Autoscaler to larger clusters is to increase the resource requests for its deployment. Both memory and CPU should be increased for large clusters, though this varies significantly with cluster size. The autoscaling algorithm stores all pods and nodes in memory, which can result in a memory footprint larger than a gigabyte in some cases. Increasing resources is typically done manually. If you find that constant resource tuning is creating an operational burden, consider using the Addon Resizer or Vertical Pod Autoscaler.
Reducing the number of Node Groups¶
Minimizing the number of node groups is one way to ensure that the Cluster Autoscaler will continue to perform well on large clusters. This may be challenging for some organizations who structure their node groups per team or per application. While this is fully supported by the Kubernetes API, this is considered to be a Cluster Autoscaler anti-pattern with repercussions for scalability. There are many reasons to use multiple node groups (e.g. Spot or GPUs), but in many cases there are alternative designs that achieve the same effect while using a small number of groups.
Ensure that:
- Pod isolation is done using Namespaces rather than Node Groups.
- This may not be possible in low-trust multi-tenant clusters.
- Pod ResourceRequests and ResourceLimits are properly set to avoid resource contention.
- Larger instance types will result in more optimal bin packing and reduced system pod overhead.
- NodeTaints or NodeSelectors are used to schedule pods as the exception, not as the rule.
- Regional resources are defined as a single EC2 Auto Scaling Group with multiple Availability Zones.
Reducing the Scan Interval¶
A low scan interval (e.g. 10 seconds) will ensure that the Cluster Autoscaler responds as quickly as possible when pods become unschedulable. However, each scan results in many API calls to the Kubernetes API and EC2 Auto Scaling Group or EKS Managed Node Group APIs. These API calls can result in rate limiting or even service unavailability for your Kubernetes Control Plane.
The default scan interval is 10 seconds, but on AWS, launching a node takes significantly longer to launch a new instance. This means that it's possible to increase the interval without significantly increasing overall scale up time. For example, if it takes 2 minutes to launch a node, changing the interval to 1 minute will result a tradeoff of 6x reduced API calls for 38% slower scale ups.
Sharding Across Node Groups¶
The Cluster Autoscaler can be configured to operate on a specific set of Node Groups. Using this functionality, it's possible to deploy multiple instances of the Cluster Autoscaler, each configured to operate on a different set of Node Groups. This strategy enables you use arbitrarily large numbers of Node Groups, trading cost for scalability. We only recommend using this as a last resort for improving performance.
The Cluster Autoscaler was not originally designed for this configuration, so there are some side effects. Since the shards do not communicate, it's possible for multiple autoscalers to attempt to schedule an unschedulable pod. This can result in unnecessary scale out of multiple Node Groups. These extra nodes will scale back in after the scale-down-delay.
metadata:
name: cluster-autoscaler
namespace: cluster-autoscaler-1
...
--nodes=1:10:k8s-worker-asg-1
--nodes=1:10:k8s-worker-asg-2
---
metadata:
name: cluster-autoscaler
namespace: cluster-autoscaler-2
...
--nodes=1:10:k8s-worker-asg-3
--nodes=1:10:k8s-worker-asg-4
Ensure that:
- Each shard is configured to point to a unique set of EC2 Auto Scaling Groups
- Each shard is deployed to a separate namespace to avoid leader election conflicts
Optimizing for Cost and Availability¶
Spot Instances¶
You can use Spot Instances in your node groups and save up to 90% off the on-demand price, with the trade-off the Spot Instances can be interrupted at any time when EC2 needs the capacity back. Insufficient Capacity Errors will occur when your EC2 Auto Scaling group cannot scale up due to lack of available capacity. Maximizing diversity by selecting many instance families can increase your chance of achieving your desired scale by tapping into many Spot capacity pools, and decrease the impact of Spot Instance interruptions on your cluster availability. Mixed Instance Policies with Spot Instances are a great way to increase diversity without increasing the number of node groups. Keep in mind, if you need guaranteed resources, use On-Demand Instances instead of Spot Instances.
It's critical that all Instance Types have similar resource capacity when configuring Mixed Instance Policies. The autoscaler's scheduling simulator uses the first InstanceType in the MixedInstancePolicy. If subsequent Instance Types are larger, resources may be wasted after a scale up. If smaller, your pods may fail to schedule on the new instances due to insufficient capacity. For example, M4, M5, M5a, and M5n instances all have similar amounts of CPU and Memory and are great candidates for a MixedInstancePolicy. The EC2 Instance Selector tool can help you identify similar instance types.
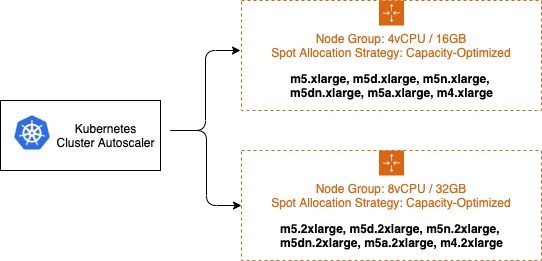
It's recommended to isolate On-Demand and Spot capacity into separate EC2 Auto Scaling groups. This is preferred over using a base capacity strategy because the scheduling properties are fundamentally different. Since Spot Instances be interrupted at any time (when EC2 needs the capacity back), users will often taint their preemptable nodes, requiring an explicit pod toleration to the preemption behavior. These taints result in different scheduling properties for the nodes, so they should be separated into multiple EC2 Auto Scaling Groups.
The Cluster Autoscaler has a concept of Expanders, which provide different strategies for selecting which Node Group to scale. The strategy --expander=least-waste is a good general purpose default, and if you're going to use multiple node groups for Spot Instance diversification (as described in the image above), it could help further cost-optimize the node groups by scaling the group which would be best utilized after the scaling activity.
Prioritizing a node group / ASG¶
You may also configure priority based autoscaling by using the Priority expander. --expander=priority enables your cluster to prioritize a node group / ASG, and if it is unable to scale for any reason, it will choose the next node group in the prioritized list. This is useful in situations where, for example, you want to use P3 instance types because their GPU provides optimal performance for your workload, but as a second option you can also use P2 instance types.
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-autoscaler-priority-expander
namespace: kube-system
data:
priorities: |-
10:
- .*p2-node-group.*
50:
- .*p3-node-group.*
Cluster Autoscaler will try to scale up the EC2 Auto Scaling group matching the name p3-node-group. If this operation does not succeed within --max-node-provision-time, it will attempt to scale an EC2 Auto Scaling group matching the name p2-node-group.
This value defaults to 15 minutes and can be reduced for more responsive node group selection, though if the value is too low, it can cause unnecessary scale outs.
Overprovisioning¶
The Cluster Autoscaler minimizes costs by ensuring that nodes are only added to the cluster when needed and are removed when unused. This significantly impacts deployment latency because many pods will be forced to wait for a node scale up before they can be scheduled. Nodes can take multiple minutes to become available, which can increase pod scheduling latency by an order of magnitude.
This can be mitigated using overprovisioning, which trades cost for scheduling latency. Overprovisioning is implemented using temporary pods with negative priority, which occupy space in the cluster. When newly created pods are unschedulable and have higher priority, the temporary pods will be preempted to make room. The temporary pods then become unschedulable, triggering the Cluster Autoscaler to scale out new overprovisioned nodes.
There are other less obvious benefits to overprovisioning. Without overprovisioning, one of the side effects of a highly utilized cluster is that pods will make less optimal scheduling decisions using the preferredDuringSchedulingIgnoredDuringExecution rule of Pod or Node Affinity. A common use case for this is to separate pods for a highly available application across availability zones using AntiAffinity. Overprovisioning can significantly increase the chance that a node of the correct zone is available.
The amount of overprovisioned capacity is a careful business decision for your organization. At its core, it's a tradeoff between performance and cost. One way to make this decision is to determine your average scale up frequency and divide it by the amount of time it takes to scale up a new node. For example, if on average you require a new node every 30 seconds and EC2 takes 30 seconds to provision a new node, a single node of overprovisioning will ensure that there's always an extra node available, reducing scheduling latency by 30 seconds at the cost of a single additional EC2 Instance. To improve zonal scheduling decisions, overprovision a number of nodes equal to the number of availability zones in your EC2 Auto Scaling Group to ensure that the scheduler can select the best zone for incoming pods.
Prevent Scale Down Eviction¶
Some workloads are expensive to evict. Big data analysis, machine learning tasks, and test runners will eventually complete, but must be restarted if interrupted. The Cluster Autoscaler will attempt to scale down any node under the scale-down-utilization-threshold, which will interrupt any remaining pods on the node. This can be prevented by ensuring that pods that are expensive to evict are protected by a label recognized by the Cluster Autoscaler.
Ensure that:
- Expensive to evict pods have the annotation
cluster-autoscaler.kubernetes.io/safe-to-evict=false
Advanced Use Cases¶
EBS Volumes¶
Persistent storage is critical for building stateful applications, such as database or distributed caches. EBS Volumes enable this use case on Kubernetes, but are limited to a specific zone. These applications can be highly available if sharded across multiple AZs using a separate EBS Volume for each AZ. The Cluster Autoscaler can then balance the scaling of the EC2 Autoscaling Groups.
Ensure that:
- Node group balancing is enabled by setting
balance-similar-node-groups=true. - Node Groups are configured with identical settings except for different availability zones and EBS Volumes.
Co-Scheduling¶
Machine learning distributed training jobs benefit significantly from the minimized latency of same-zone node configurations. These workloads deploy multiple pods to a specific zone. This can be achieved by setting Pod Affinity for all co-scheduled pods or Node Affinity using topologyKey: failure-domain.beta.kubernetes.io/zone. The Cluster Autoscaler will then scale out a specific zone to match demands. You may wish to allocate multiple EC2 Auto Scaling Groups, one per availability zone to enable failover for the entire co-scheduled workload.
Ensure that:
- Node group balancing is enabled by setting
balance-similar-node-groups=false - Node Affinity and/or Pod Preemption is used when clusters include both Regional and Zonal Node Groups.
- Use Node Affinity to force or encourage regional pods to avoid zonal Node Groups, and vice versa.
- If zonal pods schedule onto regional node groups, this will result in imbalanced capacity for your regional pods.
- If your zonal workloads can tolerate disruption and relocation, configure Pod Preemption to enable regionally scaled pods to force preemption and rescheduling on a less contested zone.
Accelerators¶
Some clusters take advantage of specialized hardware accelerators such as GPU. When scaling out, the accelerator device plugin can take several minutes to advertise the resource to the cluster. The Cluster Autoscaler has simulated that this node will have the accelerator, but until the accelerator becomes ready and updates the node's available resources, pending pods can not be scheduled on the node. This can result in repeated unnecessary scale out.
Additionally, nodes with accelerators and high CPU or Memory utilization will not be considered for scale down, even if the accelerator is unused. This behavior can be expensive due to the relative cost of accelerators. Instead, the Cluster Autoscaler can apply special rules to consider nodes for scale down if they have unoccupied accelerators.
To ensure the correct behavior for these cases, you can configure the kubelet on your accelerator nodes to label the node before it joins the cluster. The Cluster Autoscaler will use this label selector to trigger the accelerator optimized behavior.
Ensure that:
- The Kubelet for GPU nodes is configured with
--node-labels k8s.amazonaws.com/accelerator=$ACCELERATOR_TYPE - Nodes with Accelerators adhere to the identical scheduling properties rule noted above.
Scaling from 0¶
Cluster Autoscaler is capable of scaling Node Groups to and from zero, which can yield significant cost savings. It detects the CPU, memory, and GPU resources of an Auto Scaling Group by inspecting the InstanceType specified in its LaunchConfiguration or LaunchTemplate. Some pods require additional resources like WindowsENI or PrivateIPv4Address or specific NodeSelectors or Taints which cannot be discovered from the LaunchConfiguration. The Cluster Autoscaler can account for these factors by discovering them from tags on the EC2 Auto Scaling Group. For example:
Key: k8s.io/cluster-autoscaler/node-template/resources/$RESOURCE_NAME
Value: 5
Key: k8s.io/cluster-autoscaler/node-template/label/$LABEL_KEY
Value: $LABEL_VALUE
Key: k8s.io/cluster-autoscaler/node-template/taint/$TAINT_KEY
Value: NoSchedule
Note: Keep in mind, when scaling to zero your capacity is returned to EC2 and may be unavailable in the future.
Additional Parameters¶
There are many configuration options that can be used to tune the behavior and performance of the Cluster Autoscaler. A complete list of parameters is available on GitHub.
| Parameter | Description | Default |
| scan-interval | How often cluster is reevaluated for scale up or down | 10 seconds |
| max-empty-bulk-delete | Maximum number of empty nodes that can be deleted at the same time. | 10 |
| scale-down-delay-after-add | How long after scale up that scale down evaluation resumes | 10 minutes |
| scale-down-delay-after-delete | How long after node deletion that scale down evaluation resumes, defaults to scan-interval | scan-interval |
| scale-down-delay-after-failure | How long after scale down failure that scale down evaluation resumes | 3 minutes |
| scale-down-unneeded-time | How long a node should be unneeded before it is eligible for scale down | 10 minutes |
| scale-down-unready-time | How long an unready node should be unneeded before it is eligible for scale down | 20 minutes |
| scale-down-utilization-threshold | Node utilization level, defined as sum of requested resources divided by capacity, below which a node can be considered for scale down | 0.5 |
| scale-down-non-empty-candidates-count | Maximum number of non empty nodes considered in one iteration as candidates for scale down with drain. Lower value means better CA responsiveness but possible slower scale down latency. Higher value can affect CA performance with big clusters (hundreds of nodes). Set to non positive value to turn this heuristic off - CA will not limit the number of nodes it considers.“ | 30 |
| scale-down-candidates-pool-ratio | A ratio of nodes that are considered as additional non empty candidates for scale down when some candidates from previous iteration are no longer valid. Lower value means better CA responsiveness but possible slower scale down latency. Higher value can affect CA performance with big clusters (hundreds of nodes). Set to 1.0 to turn this heuristics off - CA will take all nodes as additional candidates. | 0.1 |
| scale-down-candidates-pool-min-count | Minimum number of nodes that are considered as additional non empty candidates for scale down when some candidates from previous iteration are no longer valid. When calculating the pool size for additional candidates we take max(#nodes * scale-down-candidates-pool-ratio, scale-down-candidates-pool-min-count) |
50 |
Additional Resources¶
This page contains a list of Cluster Autoscaler presentations and demos. If you'd like to add a presentation or demo here, please send a pull request.
| Presentation/Demo | Presenters |
|---|---|
| Autoscaling and Cost Optimization on Kubernetes: From 0 to 100 | Guy Templeton, Skyscanner & Jiaxin Shan, Amazon |
| SIG-Autoscaling Deep Dive | Maciek Pytel & Marcin Wielgus |