네트워크 성능 문제에 대한 EKS 워크로드 모니터링¶
DNS 스로틀링 문제에 대한 CoreDNS 트래픽 모니터링¶
DNS 집약적 워크로드를 실행하면 DNS 스로틀링으로 인해 간헐적으로 CoreDNS 장애가 발생할 수 있으며, 이로 인해 가끔 알 수 없는 Hostexception 오류가 발생할 수 있는 애플리케이션에 영향을 미칠 수 있습니다.
CoreDNS 배포에는 Kubernetes 스케줄러가 클러스터의 개별 워커 노드에서 CoreDNS 인스턴스를 실행하도록 지시하는 반선호도 정책이 있습니다. 즉, 동일한 워커 노드에 복제본을 같은 위치에 배치하지 않도록 해야 합니다. 이렇게 하면 각 복제본의 트래픽이 다른 ENI를 통해 라우팅되므로 네트워크 인터페이스당 DNS 쿼리 수가 효과적으로 줄어듭니다. 초당 1024개의 패킷 제한으로 인해 DNS 쿼리가 병목 현상을 겪는 경우 1) 코어 DNS 복제본 수를 늘리거나 2) NodeLocal DNS 캐시를 구현해 볼 수 있습니다.자세한 내용은 CoreDNS 메트릭 모니터링을 참조하십시오.
도전 과제¶
- 패킷 드롭은 몇 초 만에 발생하며 DNS 스로틀링이 실제로 발생하는지 확인하기 위해 이런 패턴을 적절하게 모니터링하는 것은 까다로울 수 있습니다.
- DNS 쿼리는 엘라스틱 네트워크 인터페이스 수준에서 조절됩니다. 따라서 병목 현상이 발생한 쿼리는 쿼리 로깅에 나타나지 않습니다.
- 플로우 로그는 모든 IP 트래픽을 캡처하지 않습니다. 예: 인스턴스가 Amazon DNS 서버에 접속할 때 생성되는 트래픽 자체 DNS 서버를 사용하는 경우 해당 DNS 서버로 향하는 모든 트래픽이 로깅됩니다.
솔루션¶
워커 노드의 DNS 조절 문제를 쉽게 식별할 수 있는 방법은 linklocal_allowance_exeded 메트릭을 캡처하는 것입니다. linklocal_allowance_exceeded는 로컬 프록시 서비스에 대한 트래픽의 PPS가 네트워크 인터페이스의 최대값을 초과하여 삭제된 패킷 수입니다. 이는 DNS 서비스, 인스턴스 메타데이터 서비스 및 Amazon Time Sync 서비스에 대한 트래픽에 영향을 미칩니다. 이 이벤트를 실시간으로 추적하는 대신 이 지표를 Amazon Managed Service for Prometheus에도 스트리밍하여 Amazon Managed Grafana에서 시각화할 수 있습니다.
Conntrack 메트릭을 사용하여 DNS 쿼리 지연 모니터링¶
CoreDNS 스로틀링/쿼리 지연을 모니터링하는 데 도움이 될 수 있는 또 다른 지표는 conntrack_allowance_available과 conntrack_allowance_exceed입니다.
연결 추적 허용량을 초과하여 발생하는 연결 장애는 다른 허용치를 초과하여 발생하는 연결 실패보다 더 큰 영향을 미칠 수 있습니다. TCP를 사용하여 데이터를 전송하는 경우, 대역폭, PPS 등과 같이 EC2 인스턴스 네트워크 허용량을 초과하여 대기열에 있거나 삭제되는 패킷은 일반적으로 TCP의 혼잡 제어 기능 덕분에 정상적으로 처리됩니다. 영향을 받은 흐름은 느려지고 손실된 패킷은 재전송됩니다. 그러나 인스턴스가 Connections Tracked 허용량을 초과하는 경우 새 연결을 위한 공간을 마련하기 위해 기존 연결 중 일부를 닫기 전까지는 새 연결을 설정할 수 없습니다.
conntrack_allowance_available 및 conntrack_allowance_exceed는 고객이 모든 인스턴스마다 달라지는 연결 추적 허용량을 모니터링하는 데 도움이 됩니다. 이런 네트워크 성능 지표를 통해 고객은 네트워크 대역폭, 초당 패킷 수 (PPS), 추적된 연결, 링크 로컬 서비스 액세스 (Amazon DNS, 인스턴스 메타 데이터 서비스, Amazon Time Sync) 와 같은 인스턴스의 네트워킹 허용량을 초과했을 때 대기 또는 삭제되는 패킷 수를 파악할 수 있습니다.
conntrack_allowance_available은 해당 인스턴스 유형의 추적된 연결 허용량에 도달하기 전에 인스턴스가 설정할 수 있는 추적된 연결 수입니다 (니트로 기반 인스턴스에서만 지원됨).
conntrack_allowance_exceed는 인스턴스의 연결 추적이 최대치를 초과하여 새 연결을 설정할 수 없어서 삭제된 패킷 수입니다.
기타 중요한 네트워크 성능 지표¶
기타 중요한 네트워크 성능 지표는 다음과 같습니다.
bw_in_allowance_exceed (이상적인 지표 값은 0이어야 함) 는 인바운드 집계 대역폭이 인스턴스의 최대값을 초과하여 대기 및/또는 삭제된 패킷 수입니다.
bw_out_allowance_exceed (이상적인 지표 값은 0이어야 함) 는 아웃바운드 총 대역폭이 해당 인스턴스의 최대값을 초과하여 대기 및/또는 삭제된 패킷 수입니다.
pps_allowance_exceed (이상적인 지표 값은 0이어야 함) 는 양방향 PPS가 인스턴스의 최대값을 초과하여 대기 및/또는 삭제된 패킷 수입니다.
네트워크 성능 문제에 대한 워크로드 모니터링을 위한 지표 캡처¶
Elastic Network Adapter (ENA) 드라이버는 위에서 설명한 네트워크 성능 메트릭이 활성화된 인스턴스로부터 해당 메트릭을 게시합니다. CloudWatch 에이전트를 사용하여 모든 네트워크 성능 지표를 CloudWatch에 게시할 수 있습니다. 자세한 내용은 블로그를 참조하십시오.
이제 위에서 설명한 지표를 캡처하여 Prometheus용 Amazon Managed Service에 저장하고 Amazon Managed Grafana를 사용하여 시각화해 보겠습니다.
사전 요구 사항¶
- ethtool - 워커 노드에 ethtool이 설치되어 있는지 확인하십시오.
- AWS 계정에 구성된 AMP 워크스페이스.지침은 AMP 사용 설명서의 워크스페이스 만들기를 참조하십시오.
- Amazon Managed Grafana 워크스페이스
프로메테우스 ethtool 익스포터 구축¶
배포에는 ethtool에서 정보를 가져와 프로메테우스 형식으로 게시하는 Python 스크립트가 포함되어 있습니다.
kubectl apply -f https://raw.githubusercontent.com/Showmax/prometheus-ethtool-exporter/master/deploy/k8s-daemonset.yaml
ADOT 컬렉터를 배포하여 ethtool 메트릭을 스크랩하고 프로메테우스용 아마존 매니지드 서비스 워크스페이스에 저장¶
OpenTelemetry용 AWS 배포판 (ADOT) 을 설치하는 각 클러스터에는 이 역할이 있어야 AWS 서비스 어카운트에 메트릭을 Prometheus용 Amazon 관리형 서비스에 저장할 수 있는 권한을 부여할 수 있습니다.다음 단계에 따라 IRSA를 사용하여 IAM 역할을 생성하고 Amazon EKS 서비스 어카운트에 연결하십시오.
eksctl create iamserviceaccount --name adot-collector --namespace default --cluster <CLUSTER_NAME> --attach-policy-arn arn:aws:iam::aws:policy/AmazonPrometheusRemoteWriteAccess --attach-policy-arn arn:aws:iam::aws:policy/AWSXrayWriteOnlyAccess --attach-policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy --region <REGION> --approve --override-existing-serviceaccounts
ADOT 컬렉터를 배포하여 프로메테우스 ethtool 익스포터의 메트릭을 스크랩하여 프로메테우스용 아마존 매니지드 서비스에 저장해 보겠습니다.
다음 절차에서는 배포를 모드 값으로 사용하는 예제 YAML 파일을 사용합니다. 이 모드는 기본 모드이며 독립 실행형 응용 프로그램과 유사하게 ADOT Collector를 배포합니다. 이 구성은 클러스터의 파드에서 스크랩한 샘플 애플리케이션과 Amazon Managed Service for Prometheus 지표로부터 OTLP 지표를 수신합니다.
curl -o collector-config-amp.yaml https://raw.githubusercontent.com/aws-observability/aws-otel-community/master/sample-configs/operator/collector-config-amp.yaml
컬렉터-config-amp.yaml에서 다음을 사용자 고유의 값으로 바꾸십시오.
* mode: deployment
* serviceAccount: adot-collector
* endpoint: "
채택 수집기가 배포되면 지표가 Amazon Prometheus에 성공적으로 저장됩니다.
Prometheus가 알림을 보내도록 Amazon 관리 서비스의 알림 관리자를 구성¶
지금까지 설명한 메트릭을 확인하기 위해 기록 규칙 및 경고 규칙을 구성해 보겠습니다.
프로메테우스용 아마존 매니지드 서비스용 ACK 컨트롤러를 사용하여 알림 및 기록 규칙을 규정할 것입니다.
프로메테우스용 Amazon 관리 서비스 서비스를 위한 ACL 컨트롤러를 배포해 보겠습니다.
export SERVICE=prometheusservice
export RELEASE_VERSION=`curl -sL https://api.github.com/repos/aws-controllers-k8s/$SERVICE-controller/releases/latest | grep '"tag_name":' | cut -d'"' -f4`
export ACK_SYSTEM_NAMESPACE=ack-system
export AWS_REGION=us-east-1
aws ecr-public get-login-password --region us-east-1 | helm registry login --username AWS --password-stdin public.ecr.aws
helm install --create-namespace -n $ACK_SYSTEM_NAMESPACE ack-$SERVICE-controller \
oci://public.ecr.aws/aws-controllers-k8s/$SERVICE-chart --version=$RELEASE_VERSION --set=aws.region=$AWS_REGION
명령을 실행하면 몇 분 후 다음 메시지가 표시됩니다.
You are now able to create Amazon Managed Service for Prometheus (AMP) resources!
The controller is running in "cluster" mode.
The controller is configured to manage AWS resources in region: "us-east-1"
The ACK controller has been successfully installed and ACK can now be used to provision an Amazon Managed Service for Prometheus workspace.
이제 경고 관리자 정의 및 규칙 그룹을 프로비저닝하기 위한 yaml 파일을 생성해 보겠습니다.
아래 파일을 rulegroup.yaml로 저장합니다.
apiVersion: prometheusservice.services.k8s.aws/v1alpha1
kind: RuleGroupsNamespace
metadata:
name: default-rule
spec:
workspaceID: <Your WORKSPACE-ID>
name: default-rule
configuration: |
groups:
- name: ppsallowance
rules:
- record: metric:pps_allowance_exceeded
expr: rate(node_net_ethtool{device="eth0",type="pps_allowance_exceeded"}[30s])
- alert: PPSAllowanceExceeded
expr: rate(node_net_ethtool{device="eth0",type="pps_allowance_exceeded"} [30s]) > 0
labels:
severity: critical
annotations:
summary: Connections dropped due to total allowance exceeding for the (instance {{ $labels.instance }})
description: "PPSAllowanceExceeded is greater than 0"
- name: bw_in
rules:
- record: metric:bw_in_allowance_exceeded
expr: rate(node_net_ethtool{device="eth0",type="bw_in_allowance_exceeded"}[30s])
- alert: BWINAllowanceExceeded
expr: rate(node_net_ethtool{device="eth0",type="bw_in_allowance_exceeded"} [30s]) > 0
labels:
severity: critical
annotations:
summary: Connections dropped due to total allowance exceeding for the (instance {{ $labels.instance }})
description: "BWInAllowanceExceeded is greater than 0"
- name: bw_out
rules:
- record: metric:bw_out_allowance_exceeded
expr: rate(node_net_ethtool{device="eth0",type="bw_out_allowance_exceeded"}[30s])
- alert: BWOutAllowanceExceeded
expr: rate(node_net_ethtool{device="eth0",type="bw_out_allowance_exceeded"} [30s]) > 0
labels:
severity: critical
annotations:
summary: Connections dropped due to total allowance exceeding for the (instance {{ $labels.instance }})
description: "BWoutAllowanceExceeded is greater than 0"
- name: conntrack
rules:
- record: metric:conntrack_allowance_exceeded
expr: rate(node_net_ethtool{device="eth0",type="conntrack_allowance_exceeded"}[30s])
- alert: ConntrackAllowanceExceeded
expr: rate(node_net_ethtool{device="eth0",type="conntrack_allowance_exceeded"} [30s]) > 0
labels:
severity: critical
annotations:
summary: Connections dropped due to total allowance exceeding for the (instance {{ $labels.instance }})
description: "ConnTrackAllowanceExceeded is greater than 0"
- name: linklocal
rules:
- record: metric:linklocal_allowance_exceeded
expr: rate(node_net_ethtool{device="eth0",type="linklocal_allowance_exceeded"}[30s])
- alert: LinkLocalAllowanceExceeded
expr: rate(node_net_ethtool{device="eth0",type="linklocal_allowance_exceeded"} [30s]) > 0
labels:
severity: critical
annotations:
summary: Packets dropped due to PPS rate allowance exceeded for local services (instance {{ $labels.instance }})
description: "LinkLocalAllowanceExceeded is greater than 0"
WORKSPACE-ID를 사용 중인 작업 공간의 작업 영역 ID로 바꾸십시오.
이제 알림 관리자 정의를 구성해 보겠습니다.아래 파일을 alertmanager.yaml으로 저장합니다.
apiVersion: prometheusservice.services.k8s.aws/v1alpha1
kind: AlertManagerDefinition
metadata:
name: alert-manager
spec:
workspaceID: <Your WORKSPACE-ID >
configuration: |
alertmanager_config: |
route:
receiver: default_receiver
receivers:
- name: default_receiver
sns_configs:
- topic_arn: TOPIC-ARN
sigv4:
region: REGION
message: |
alert_type: {{ .CommonLabels.alertname }}
event_type: {{ .CommonLabels.event_type }}
WORKSPACE-ID를 새 작업 공간의 작업 공간 ID로, TOPIC-ARN을 알림을 보내려는 Amazon 단순 알림 서비스 주제의 ARN으로, 그리고 REGION을 워크로드의 현재 지역으로 대체합니다. 작업 영역에 Amazon SNS로 메시지를 보낼 권한이 있는지 확인하십시오.
아마존 매니지드 그라파나에서 ethtool 메트릭을 시각화¶
Amazon Managed Grafana 내에서 지표를 시각화하고 대시보드를 구축해 보겠습니다.프로메테우스용 아마존 매니지드 서비스를 아마존 매니지드 그라파나 콘솔 내에서 데이터 소스로 구성하십시오.지침은 아마존 프로메테우스를 데이터 소스로 추가를 참조하십시오.
이제 아마존 매니지드 그라파나의 메트릭을 살펴보겠습니다. 탐색 버튼을 클릭하고 ethtool을 검색하세요.
rate (node_net_ethtool {device="eth0", type="linklocal_allowance_Exceed "} [30s]) 쿼리를 사용하여 linklocal_allowance_Exceed 지표에 대한 대시보드를 만들어 보겠습니다.그러면 아래 대시보드가 나타납니다.
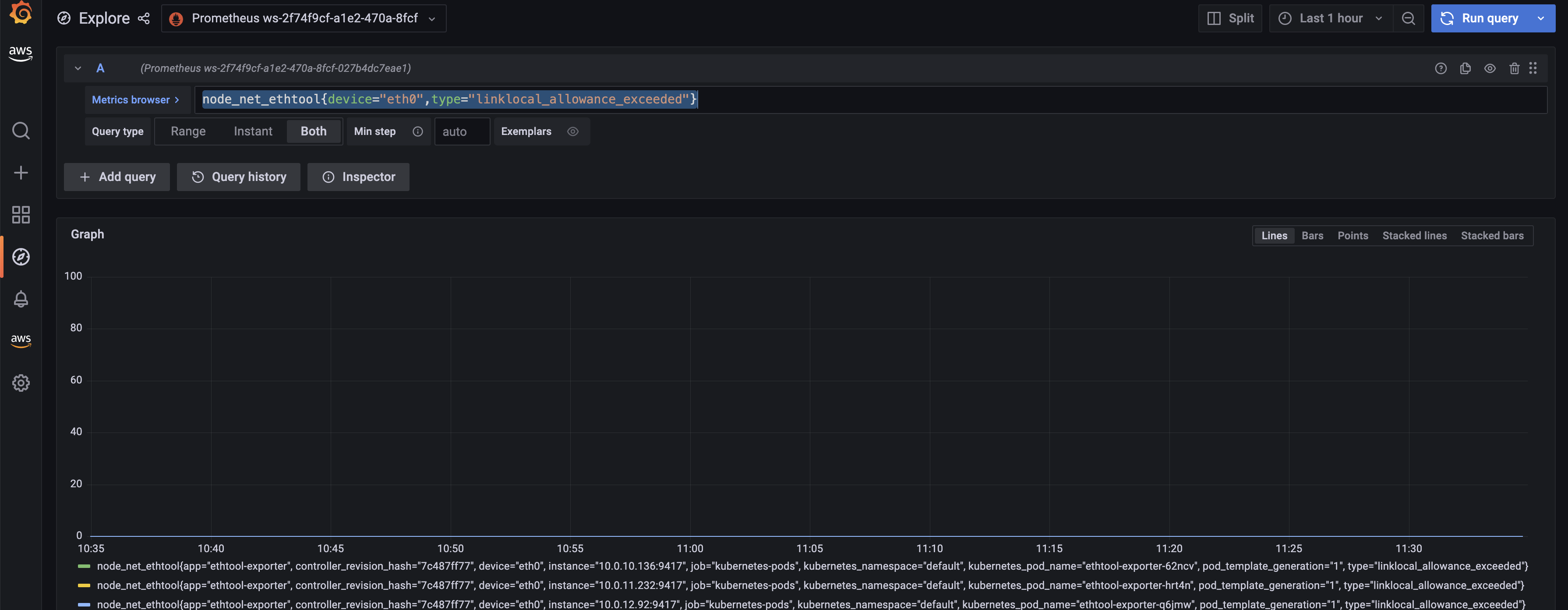
값이 0이므로 삭제된 패킷이 없음을 분명히 알 수 있습니다.
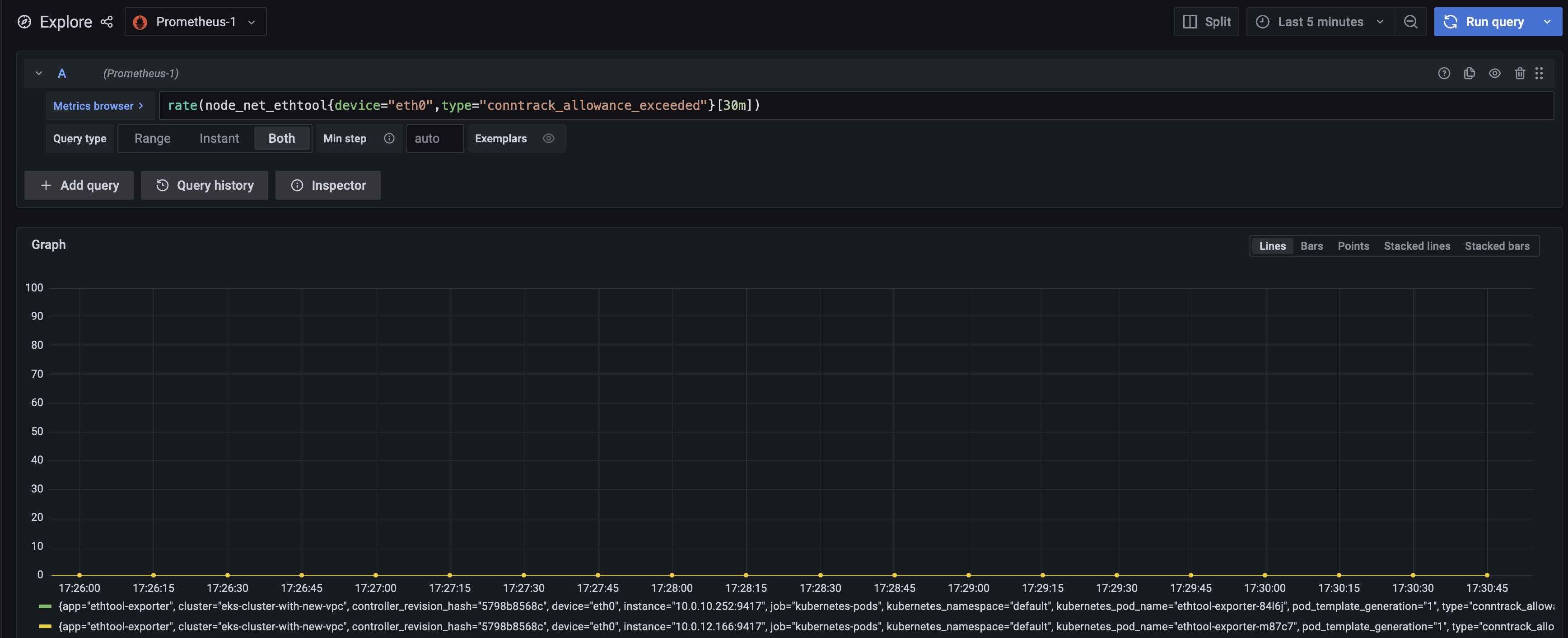
rate (node_net_ethtool {device="eth0", type="conntrack_allowance_Exceed "} [30s]) 쿼리를 사용하여 conntrack_allowance_Exceed 메트릭에 대한 대시보드를 만들어 보겠습니다.결과는 아래 대시보드와 같습니다.
여기에 설명된 대로 클라우드워치 에이전트를 실행하면 conntrack_allowance_exceed 지표를 CloudWatch에서 시각화할 수 있습니다. CloudWatch의 결과 대시보드는 다음과 같이 표시됩니다.
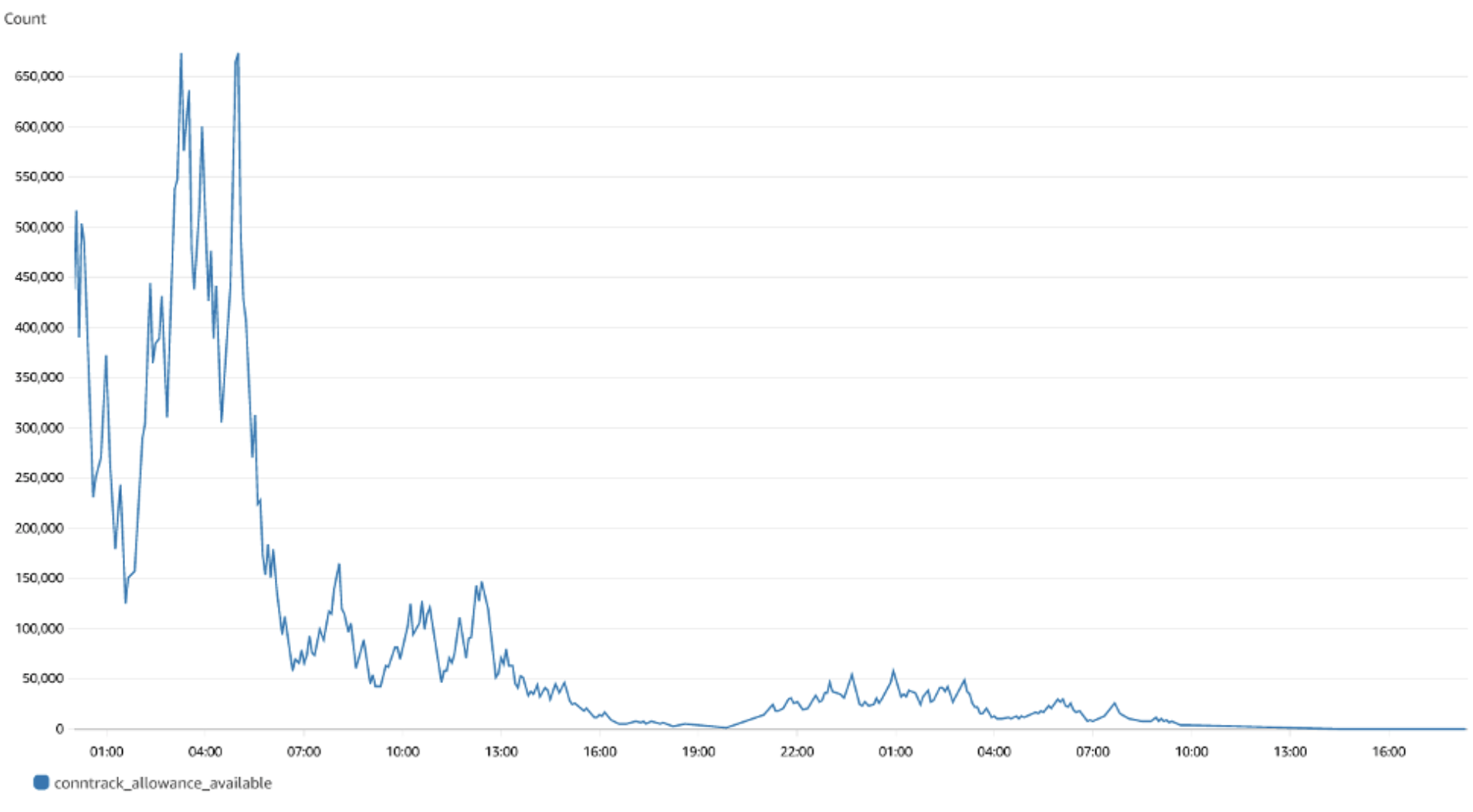
값이 0이므로 삭제된 패킷이 없음을 분명히 알 수 있습니다.Nitro 기반 인스턴스를 사용하는 경우 'conntrack_allowance_available'에 대한 유사한 대시보드를 만들고 EC2 인스턴스의 연결을 사전에 모니터링할 수 있습니다.Amazon Managed Grafana에서 슬랙, SNS, Pagerduty 등에 알림을 보내도록 알림을 구성하여 이를 더욱 확장할 수 있습니다.