신뢰성을 위한 Amazon EKS 모범 사례 가이드¶
이 섹션에서는 EKS에서 실행되는 워크로드의 복원력과 가용성을 높이는 방법에 대한 지침을 제공합니다.
이 가이드를 사용하는 방법¶
이 안내서는 EKS에서 가용성이 높고 내결함성이 있는 서비스를 개발하고 운영하려는 개발자와 설계자를 대상으로 합니다. 이 가이드는 보다 쉽게 사용할 수 있도록 다양한 주제 영역으로 구성되어 있습니다. 각 항목은 간략한 개요로 시작하여 EKS 클러스터의 신뢰성을 위한 권장 사항 및 모범 사례 목록이 이어집니다.
소개¶
EKS의 신뢰성 모범 사례는 다음 주제에 따라 그룹화되었습니다.
- 애플리케이션
- 컨트롤 플레인
- 데이터 플레인
무엇이 시스템을 신뢰할 수 있게 만드나요? 일정 기간의 환경 변화에도 불구하고 시스템이 일관되게 작동하고 요구 사항을 충족할 수 있다면 신뢰할 수 있다고 할 수 있습니다. 이를 위해서는 시스템이 장애를 감지하고 자동으로 복구하며 수요에 따라 확장할 수 있어야 합니다.
고객은 Kubernetes를 기반으로 사용하여 업무상 중요한 애플리케이션 및 서비스를 안정적으로 운영할 수 있습니다. 그러나 컨테이너 기반 애플리케이션 설계 원칙을 통합하는 것 외에도 워크로드를 안정적으로 실행하려면 신뢰할 수 있는 인프라가 필요합니다. 쿠버네티스에서 인프라는 컨트롤 플레인과 데이터 플레인으로 구성됩니다.
EKS는 가용성과 내결함성을 제공하도록 설계된 프로덕션 등급의 Kubernetes 컨트롤 플레인을 제공합니다.
EKS에서 AWS는 쿠버네티스 컨트롤 플레인의 신뢰성을 책임집니다. EKS는 AWS 리전의 세 가용 영역에서 쿠버네티스 컨트롤 플레인을 실행합니다. 쿠버네티스 API 서버 및 etcd 클러스터의 가용성과 확장성을 자동으로 관리합니다.
데이터 플레인의 신뢰성에 대한 책임은 사용자, 고객, AWS 간에 공유됩니다. EKS는 Kubernetes 데이터 플레인에 대한 세 가지 옵션을 제공합니다. 가장 많이 관리되는 옵션인 Fargate는 데이터 플레인의 프로비저닝 및 확장을 처리합니다. 두 번째 옵션인 관리형 노드 그룹화는 데이터 플레인의 프로비저닝 및 업데이트를 처리합니다. 마지막으로, 자체 관리형 노드는 데이터 플레인에 대한 관리가 가장 적은 옵션입니다. AWS 관리형 데이터 플레인을 더 많이 사용할수록 책임은 줄어듭니다.
관리형 노드 그룹은 EC2 노드의 프로비저닝 및 수명 주기 관리를 자동화합니다. EKS API (EKS 콘솔, AWS API, AWS CLI, CloudFormation, Terraform 또는 eksctl 사용)를 사용하여 관리형 노드를 생성, 확장 및 업그레이드할 수 있습니다. 관리형 노드는 계정에서 EKS에 최적화된 Amazon Linux 2 EC2 인스턴스를 실행하며, SSH 액세스를 활성화하여 사용자 지정 소프트웨어 패키지를 설치할 수 있습니다. 관리형 노드를 프로비저닝하면 여러 가용 영역에 걸쳐 있을 수 있는 EKS 관리형 Auto Scaling 그룹의 일부로 실행되므로 관리형 노드를 생성할 때 제공하는 서브넷을 통해 이를 제어할 수 있습니다. 또한 EKS는 관리형 노드에 자동으로 태그를 지정하여 클러스터 오토스케일러에서 사용할 수 있도록 합니다.
Amazon EKS는 관리형 노드 그룹의 CVE 및 보안 패치에 대한 공동 책임 모델을 따릅니다. 관리형 노드는 Amazon EKS에 최적화된 AMI들을 실행하므로 Amazon EKS는 버그 수정 시 이러한 AMI들의 패치 버전을 만들 책임이 있습니다. 하지만 이러한 패치가 적용된 AMI 버전을 관리형 노드 그룹에 배포하는 것은 사용자의 책임입니다.
EKS는 업데이트 프로세스를 시작해야 하지만 노드 업데이트도 관리합니다. 관리형 노드 업데이트 프로세스는 EKS 설명서에 설명되어 있습니다.
자체 관리형 노드를 실행하는 경우 Amazon EKS에 최적화된 Linux AMI를 사용하여 워커 노드를 생성할 수 있습니다. AMI와 노드의 패치 및 업그레이드는 사용자가 담당합니다. eksctl, CloudFormation 또는 코드형 인프라 도구를 사용하여 자체 관리형 노드를 프로비저닝하는 것이 가장 좋습니다. 이렇게 하면 자체 관리형 노드 업그레이드를 쉽게 할 수 있기 때문입니다. 마이그레이션 프로세스에서는 이전 노드 그룹을 NoSchedule로 taints하고 새 스택이 기존 파드 워크로드를 수용할 준비가 되면 노드를 drains하기 때문에 워커 노드를 업데이트할 때 새 노드로 마이그레이션하는 것을 고려해 보십시오. 하지만 자체 관리형 노드의 in-place 업그레이드를 수행할 수도 있습니다.
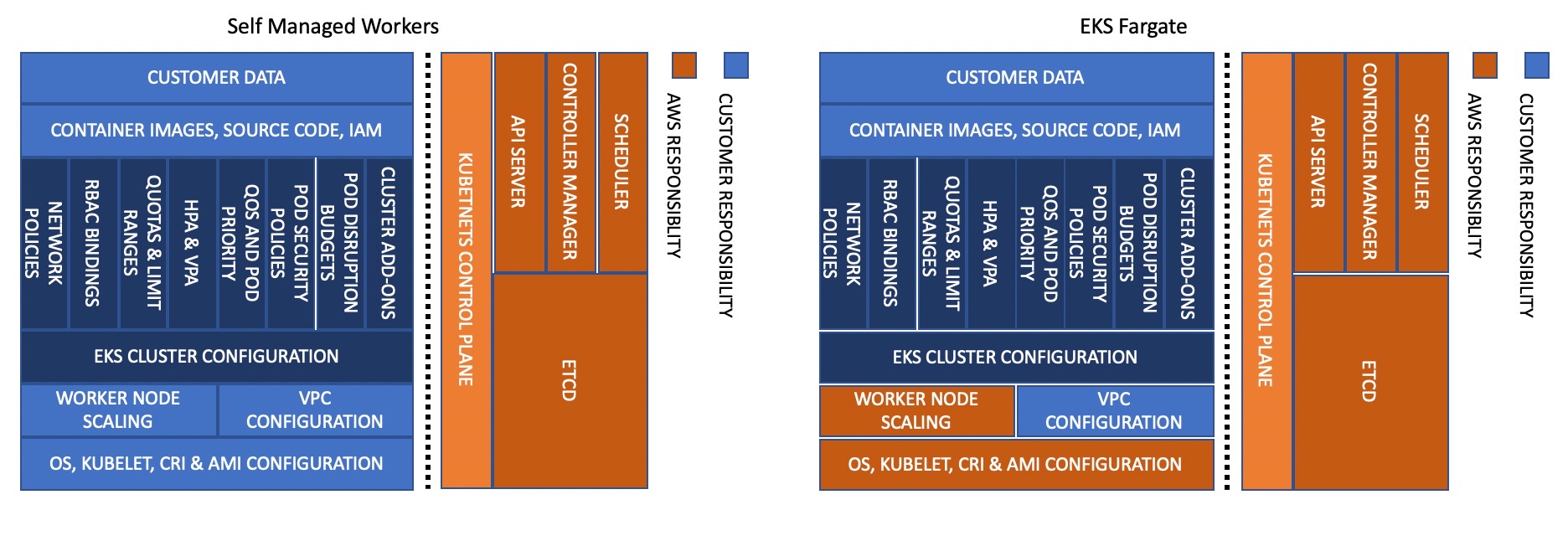
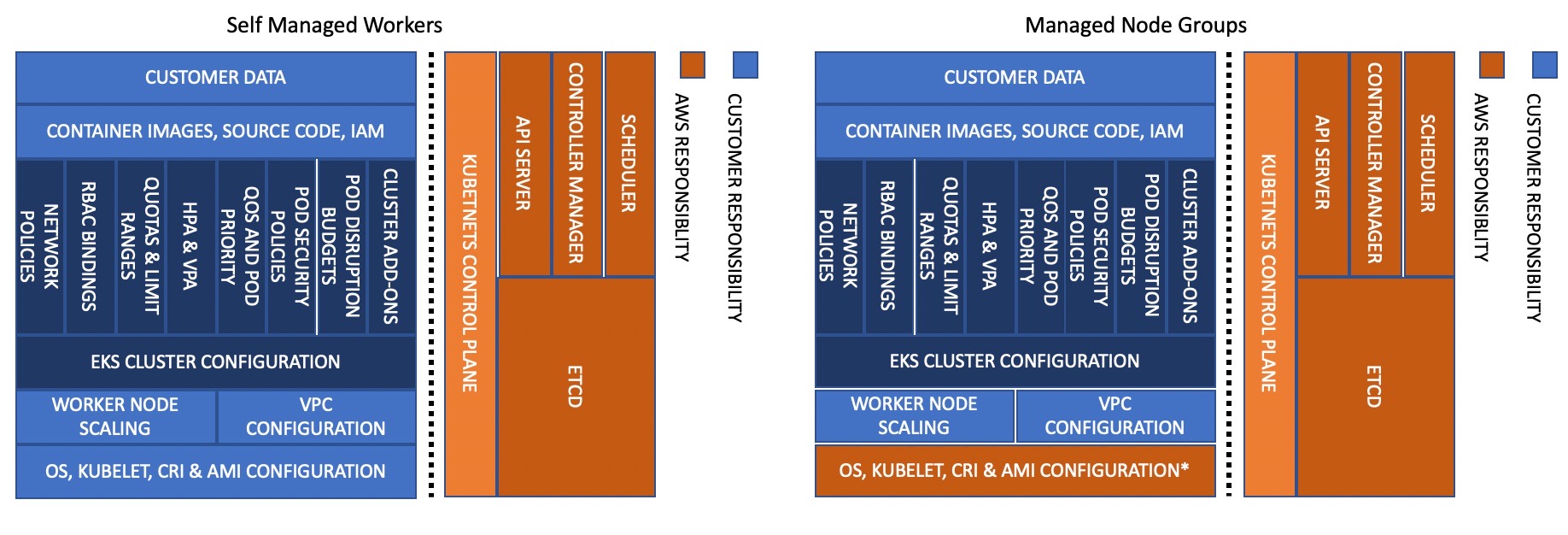
이 가이드에는 EKS 데이터 플레인, Kubernetes 핵심 구성 요소 및 애플리케이션의 신뢰성을 개선하는 데 사용할 수 있는 일련의 권장 사항이 포함되어 있습니다.
피드백¶
이 가이드는 광범위한 EKS/Kubernetes 커뮤니티로부터 직접적인 피드백과 제안을 수집하기 위해 GitHub에 게시 되었습니다. 가이드에 포함시켜야 한다고 생각되는 모범 사례가 있다면 GitHub 리포지토리에 문제를 제출하거나 PR을 제출해 주세요. 서비스에 새로운 기능이 추가되거나 새로운 모범 사례가 개발되면 가이드를 정기적으로 업데이트할 계획입니다.