Custom Scheduler for Binpacking¶
Binpacking directly influences the cost performance of your EKS cluster. Both Cluster Autoscaler and Karpenter, as node provisioners, can efficiently scales nodes in and out, but without a binpacking custom scheduler, you might end up with a scenario where nodes are underutilized due to inefficient pod distribution at the pod scheduling time.
- Better Binpacking: When pods are tightly packed onto fewer nodes, node provisioner (Cluster Autoscaler or Karpenter) can more effectively scale down unused nodes, reducing costs.
- Poor Binpacking: If pods are spread out inefficiently across many nodes, node provisioner might struggle to find opportunities to scale down, leading to resource waste.
Demonstration¶
Poor Binpacking with the default kube-scheduler:
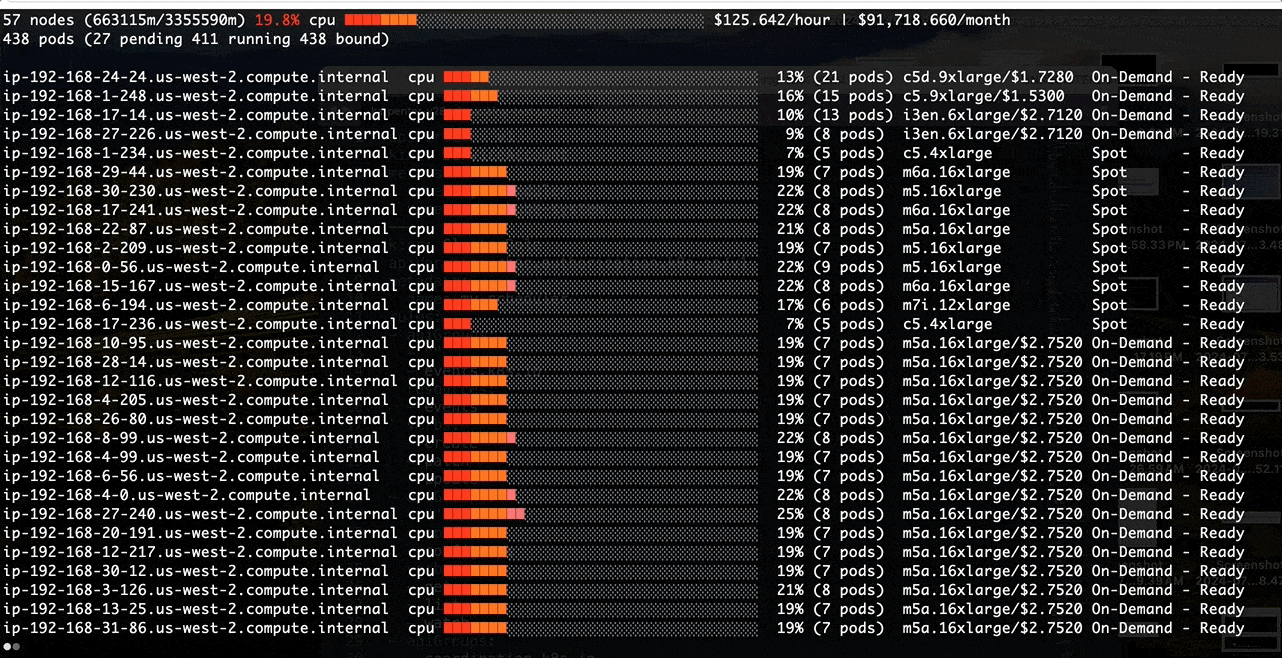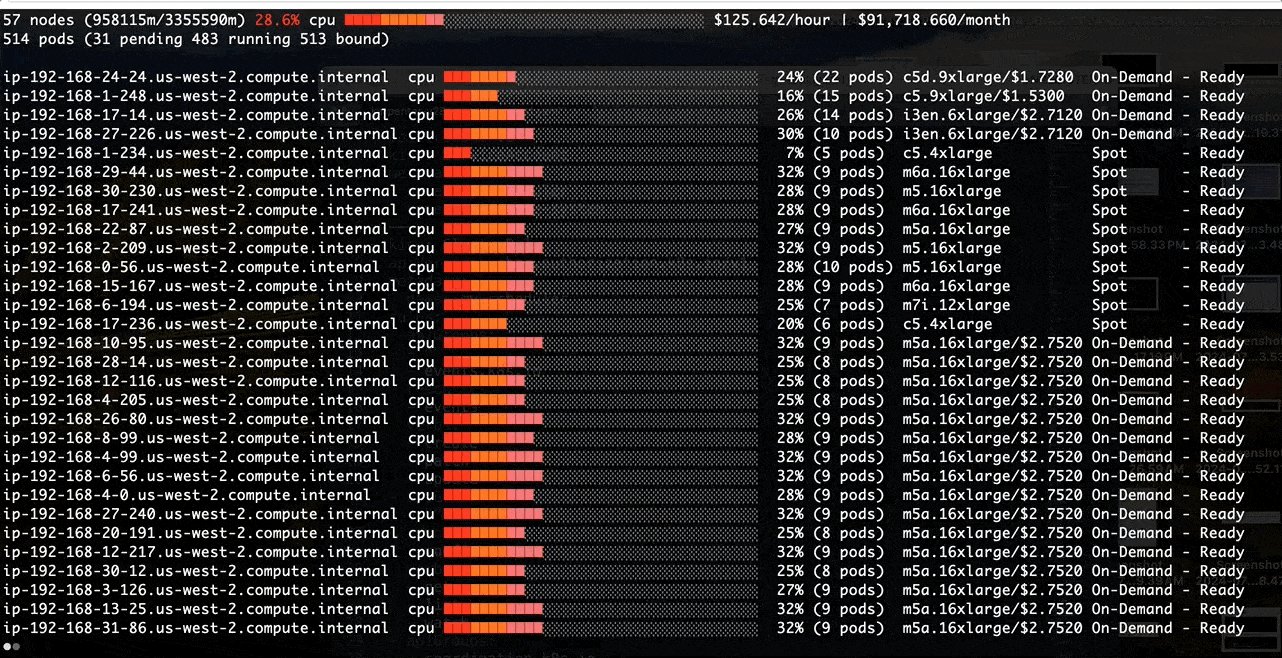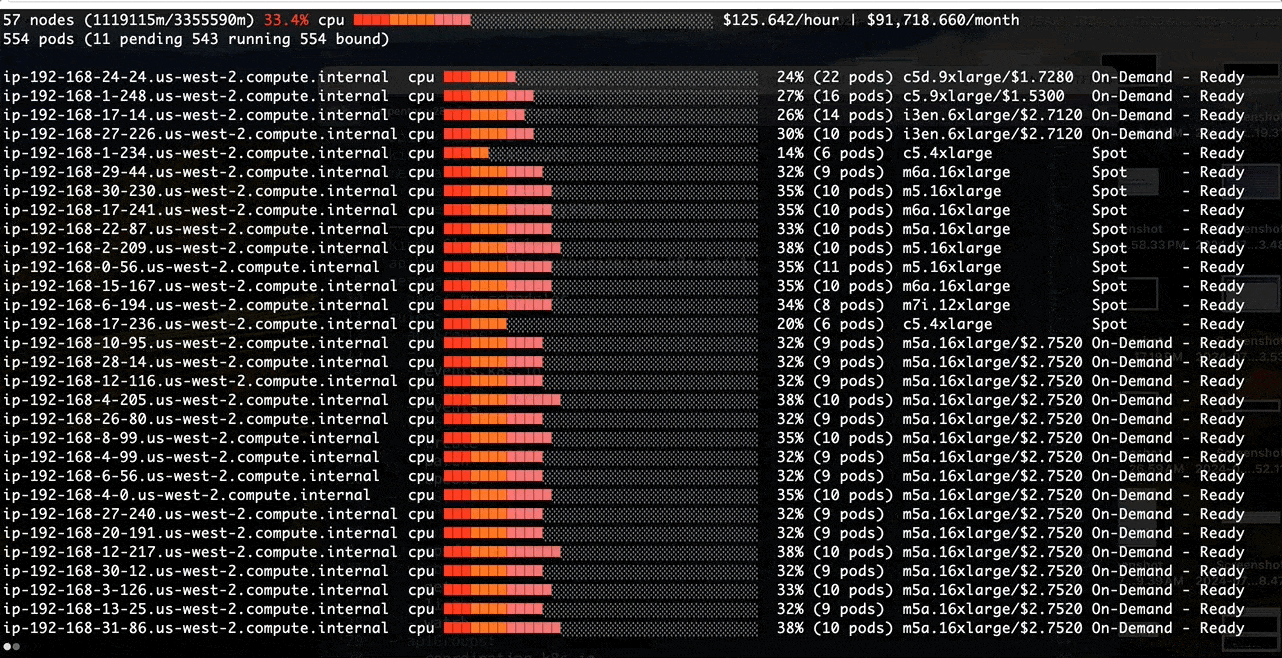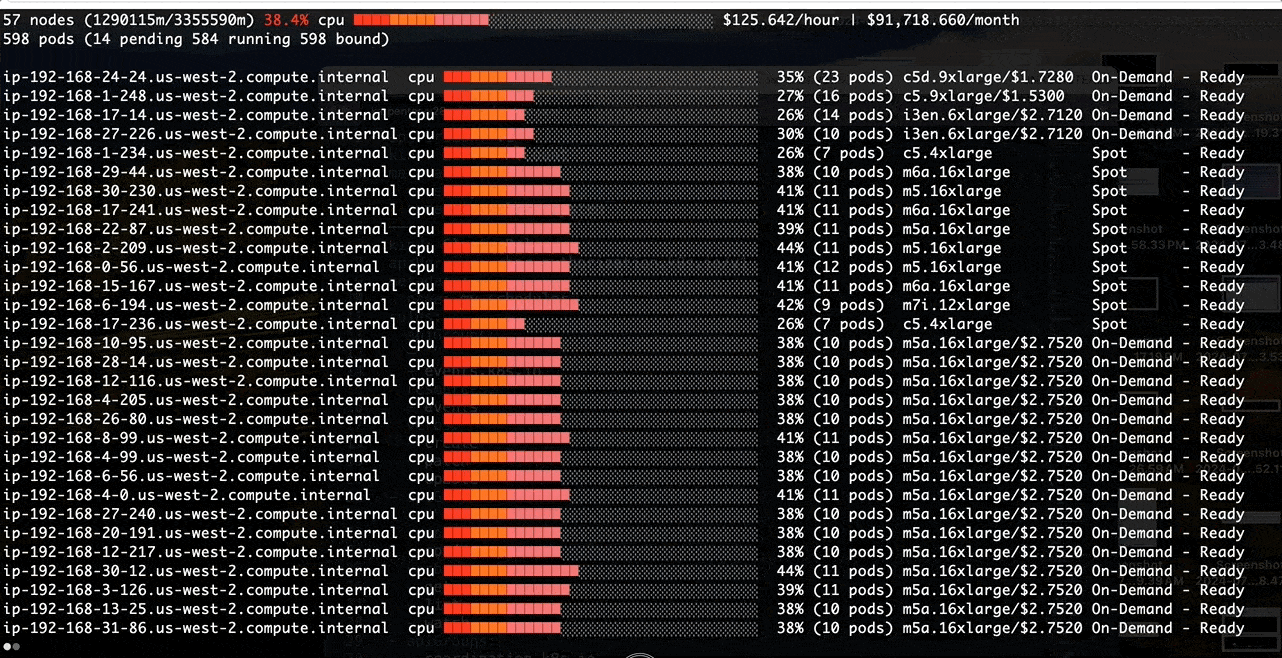
Better Binpacking with a Custom Scheduler:
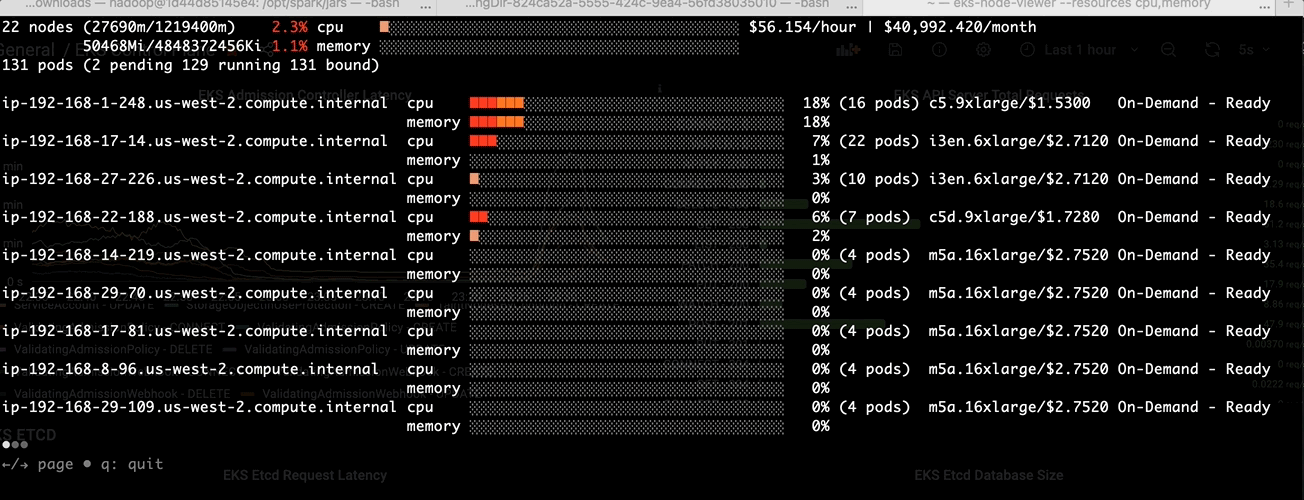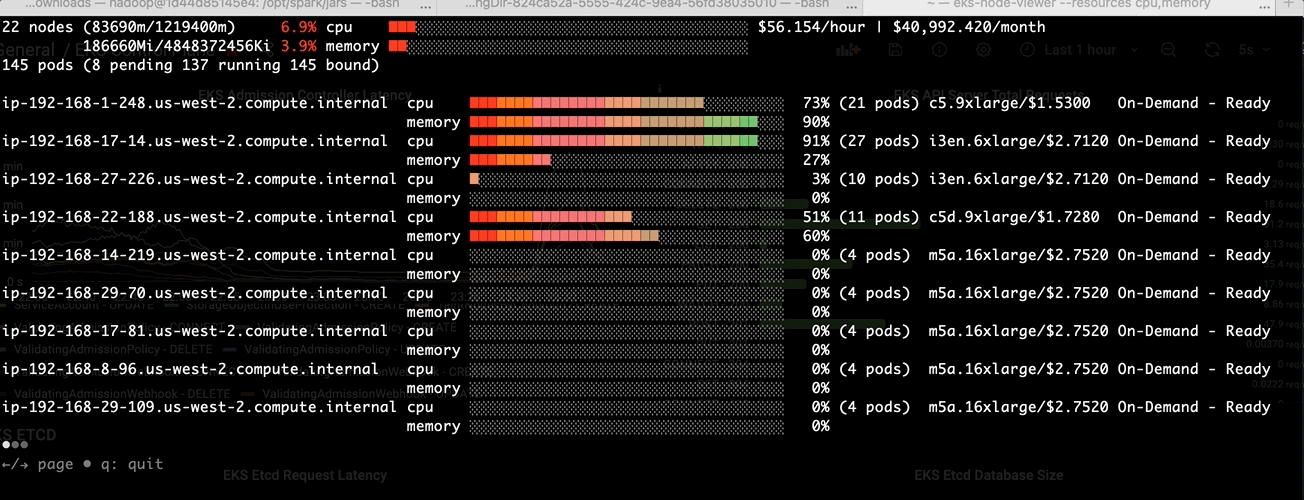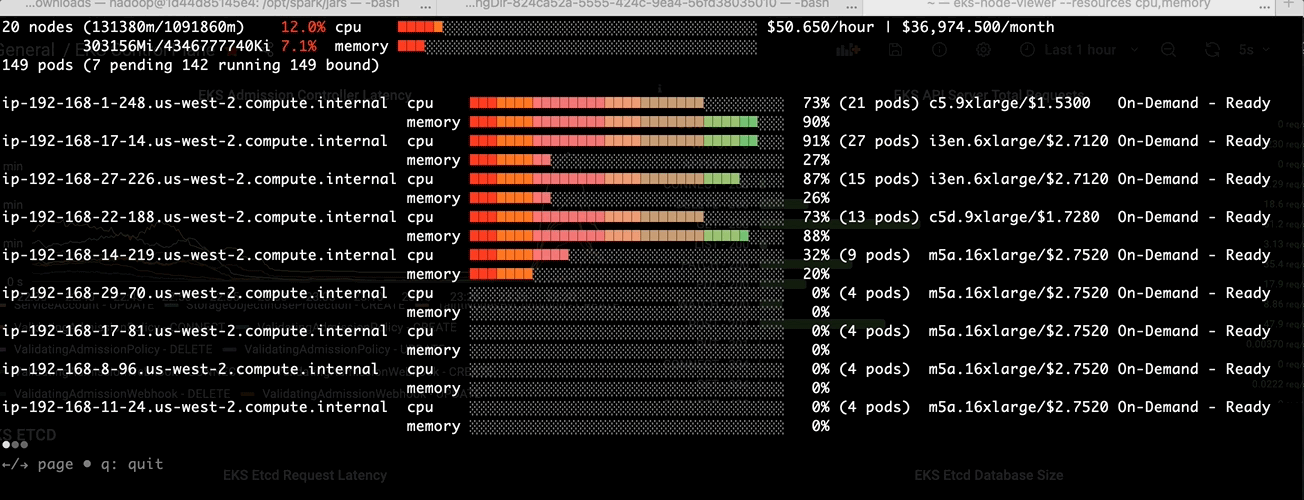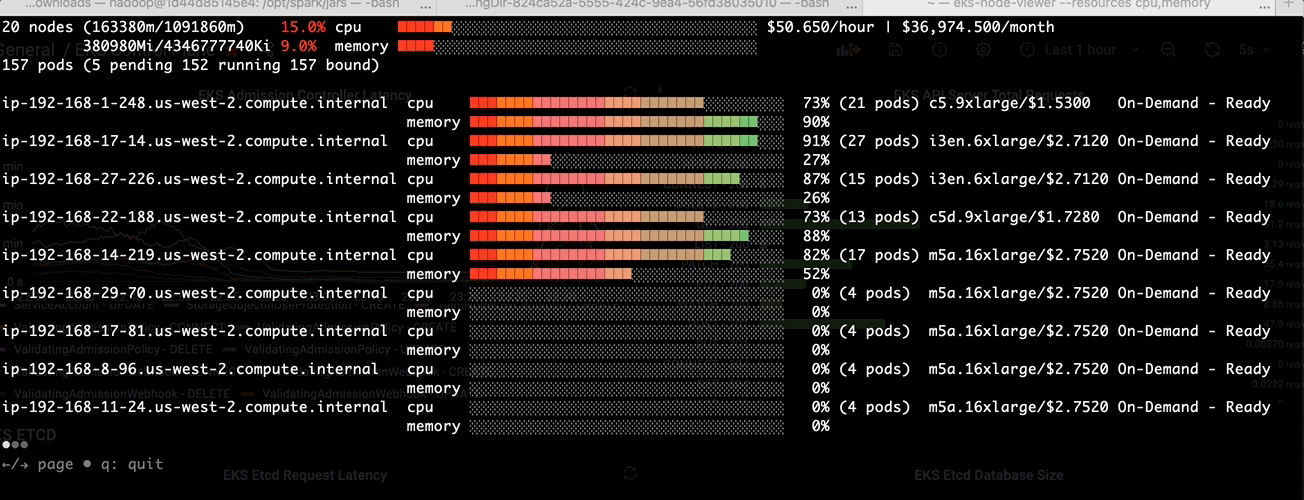
Before we tackle the binpacking issue in Amazon EMR on EKS, let’s install a node viewer tool - eks-node-viewer. It provides enhanced visibility into the EKS nodes utilization, helping with real-time monitoring, debugging, and optimization efforts. In this case, we use it to visualize dynamic node and pod allocation within an EKS cluster for tracking the binpacking performance.
Install eks-node-viewer¶
eks-node-viewer:https://github.com/awslabs/eks-node-viewer
HomeBrew
brew tap aws/tap
brew install eks-node-viewer
Manual
go install github.com/awslabs/eks-node-viewer/cmd/eks-node-viewer@latest
Quick Start:
eks-node-viewer --resources cpu,memory
Helm install Binpacking Custom Scheduler¶
In the scheduling-plugin NodeResourcesFit of kube-scheduler, there are two scoring strategies that support the bin packing of resources: MostAllocated and RequestedToCapacityRatio. We created a custom scheduler based on the MostAllocated strategy. See the K8s’s Resource Bin Packing documentation for more details.
Run the following command to install the custom scheduler:
# download the project
git clone https://github.com/aws-samples/custom-scheduler-eks
cd custom-scheduler-eks/deploy
# install
helm install my-scheduler charts/custom-scheduler-eks --set eksVersion=1.33 --set schedulerName=my-scheduler -n kube-system
NOTE: If your binpacking pod throttles for a large scale workload, increase the QPS and Burst values in your local "charts/custom-scheduler-eks/values.yaml" file, then install again:
clientConnection:
burst: 200
qps: 100
An example of throttle error from the pod logs:
I1030 23:19:48.258159 1 request.go:697] Waited for 1.93509847s due to client-side throttling, not priority and fairness, request: POST:https://10.100.0.1:443/apis/events.k8s.io/v1/namespa...vents
I1030 23:19:58.258457 1 request.go:697] Waited for 1.905177346s due to client-side throttling, not priority and fairness, request: POST:https://10.100.0.1:443/apis/events.k8s.io/v1/namespa...
View scheduler metrics¶
- Check metrics manually:
kubectl -n kube-system port-forward deploy/custom-scheduler-eks 10259
curl -k -H "Authorization: Bearer $(kubectl create token -n prometheus amp-iamproxy-ingest-service-account)" https://localhost:10259/metrics | grep "scheduler_"
Note: we used Prometheus service account token for authentication. Replace "amp-iamproxy-ingest-service-account" and "prometheus" with your actual Prometheus service account and namespace.
- Verify targets appear in Prometheus UI
kubectl port-forward svc/prometheus-operated -n prometheus 9090:9090
# paste the following url to a web browser, then search the metrics by a prefix scheduler_
http://localhost:9090/query
Validate the custom scheduler¶
- Step1: Launch the node viewer in a terminal:
eks-node-viewer --resources cpu,memory
- Step 2: Add the custom scheduler to an EMR on EKS job either via a Spark config or via Pod Templates. For exmaple:
sample-job.sh (last line)
aws emr-containers start-job-run \
--virtual-cluster-id $VIRTUAL_CLUSTER_ID \
--name test-custom-scheduler \
--execution-role-arn $EMR_ROLE_ARN \
--release-label emr-7.8.0-latest \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "local:///usr/lib/spark/examples/jars/spark-examples.jar",
"entryPointArguments": ["1000000"],
"sparkSubmitParameters": "--class org.apache.spark.examples.SparkPi --conf spark.executor.instances=10" }}' \
--configuration-overrides '{
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.kubernetes.scheduler.name": "my-scheduler" }}]}'
OR sample-pod-template.yaml (line #3)
kind: Pod
spec:
schedulerName: my-scheduler
volumes:
- name: spark-local-dir-1
emptyDir: {}
containers:
- name: spark-kubernetes-executor
volumeMounts:
- name: spark-local-dir-1
mountPath: /data1
readOnly: false
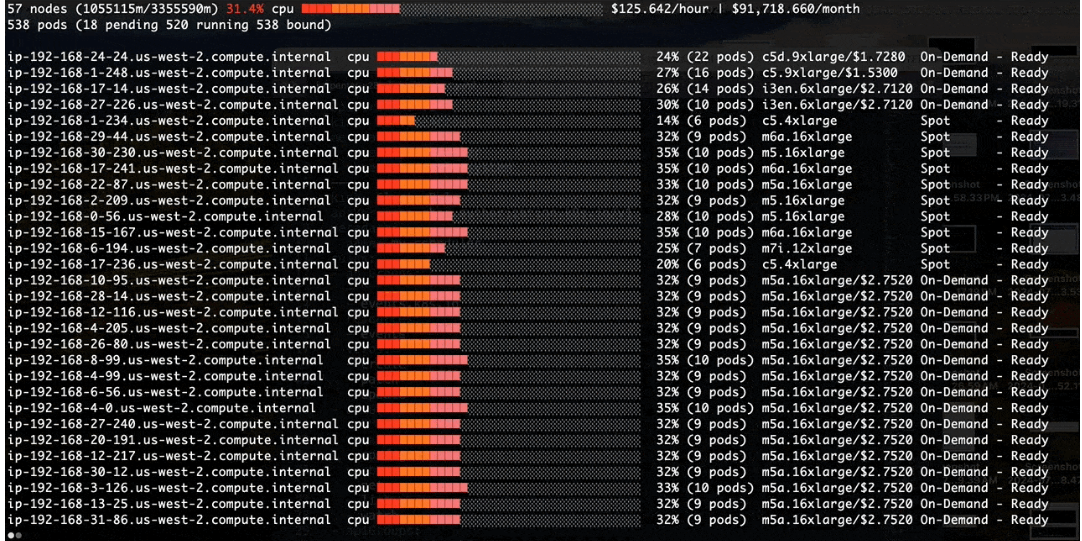
Step3: Monitor via eks-node-viewer
-Before apply the change in pod template:-
-After the change:-
- Higher resource usage per node at pod scheduling time
- Over 50% of cost reduction since Karpenter was terminating idle EC2 nodes at the same time
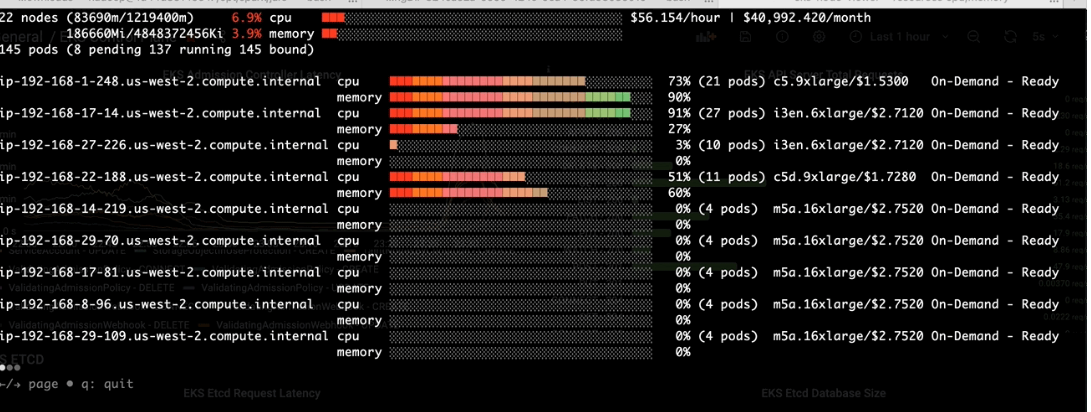
Consideration:
- At pod launch, the custom scheduler can optimize resource utilization by fitting as many pods as possible onto a single EC2 node. This approach minimizes pod distribution across multiple nodes, leading to higher resource utilization and improved cost efficiency.
- Dynamic Resource Allocation (DRA) requires shuffle tracking to be enabled because Spark on Kubernetes does not yet support an external shuffle service. Consequently, we have observed that idle EC2 nodes sometimes fail to scale down due to the shuffle data tracking requirement. Using a Binpack scheduler can help reduce the likelihood of long-running idle nodes with leftover shuffle data, resulting a better DRA outcome.
- Karpenter’s consolidation policy remains essential for reducing underutilized or empty nodes. This is particularly beneficial for long-running jobs where pods are scattered across underutilized EC2 nodes.
- After implementing a custom scheduler for binpacking, it's recommended to adjust the consolidation frequency to be less aggressive.