EMR Containers integration with FSx for Lustre¶
Amazon EKS clusters provide the compute and ephemeral storage for Spark workloads. Ephemeral storage provided by EKS is allocated from the EKS worker node's disk storage and the lifecycle of the storage is bound by the lifecycle of the driver and executor pod.
Need for durable storage:
When multiple spark applications are executed as part of a data pipeline, there are scenarios where data from one spark application is passed to subsequent spark applications - in this case data can be persisted in S3. Alternatively, this data can also be persisted in FSx for Lustre. FSx for Lustre provides a fully managed, scalable, POSIX compliant native filesystem interface for the data in s3. With FSx, your torage is decoupled from your compute and has its own lifecycle.
FSx for Lustre Volumes can be mounted on spark driver and executor pods through static and dynamic provisioning.
Data used in the below example is from AWS Open data Registry
FSx for Lustre POSIX permissions¶
When a Lustre filesystem is mounted to driver and executor pods, and if the S3 objects does not have required metadata, the mounted volume defaults
ownership of the file system to root. EMR on EKS executes the driver and executor pods with UID(999), GID (1000) and groups(1000 and 65534).
In this scenario, the spark application has read only access to the mounted Lustre file system. Below are a few approaches that can be considered:
Tag Metadata to S3 object¶
Applications writing to S3 can tag the S3 objects with the metadata that FSx for Lustre requires.
Walkthrough: Attaching POSIX permissions when uploading objects into an S3 bucket provides a guided tutorial. FSx for Lustre will convert this tagged metadata to corresponding POSIX permissions when mounting Lustre file system to the driver and executor pods.
EMR on EKS spawns the driver and executor pods as non-root user(UID -999, GID - 1000, groups - 1000, 65534).
To enable the spark application to write to the mounted file system, (UID - 999) can be made as the file-owner and supplemental group 65534 be made as the file-group.
For S3 objects that already exists with no metadata tagging, there can be a process that recursively tags all the S3 objects with the required metadata.
Below is an example:
1. Create FSx for Lustre file system to the S3 prefix.
2. Create Persistent Volume and Persistent Volume claim for the created FSx for Lustre file system
3. Run a pod as root user with FSx for Lustre mounted with the PVC created in Step 2.
```
apiVersion: v1
kind: Pod
metadata:
name: chmod-fsx-pod
namespace: test-demo
spec:
containers:
- name: ownership-change
image: amazonlinux:2
command: ["sh", "-c", "chown -hR +999:+65534 /data"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: fsx-static-root-claim
```
Run a data repository task with import path and export path pointing to the same S3 prefix. This will export the POSIX permission from FSx for Lustre file system as metadata, that is tagged on S3 objects.
Now that the S3 objects are tagged with metadata, the spark application with FSx for Lustre filesystem mounted will have write access.
Static Provisioning¶
Provision a FSx for Lustre cluster¶
FSx for Luster can also be provisioned through aws cli
How to decide what type of FSx for Lustre file system you need ?
Create a Security Group to attach to FSx for Lustre file system as below
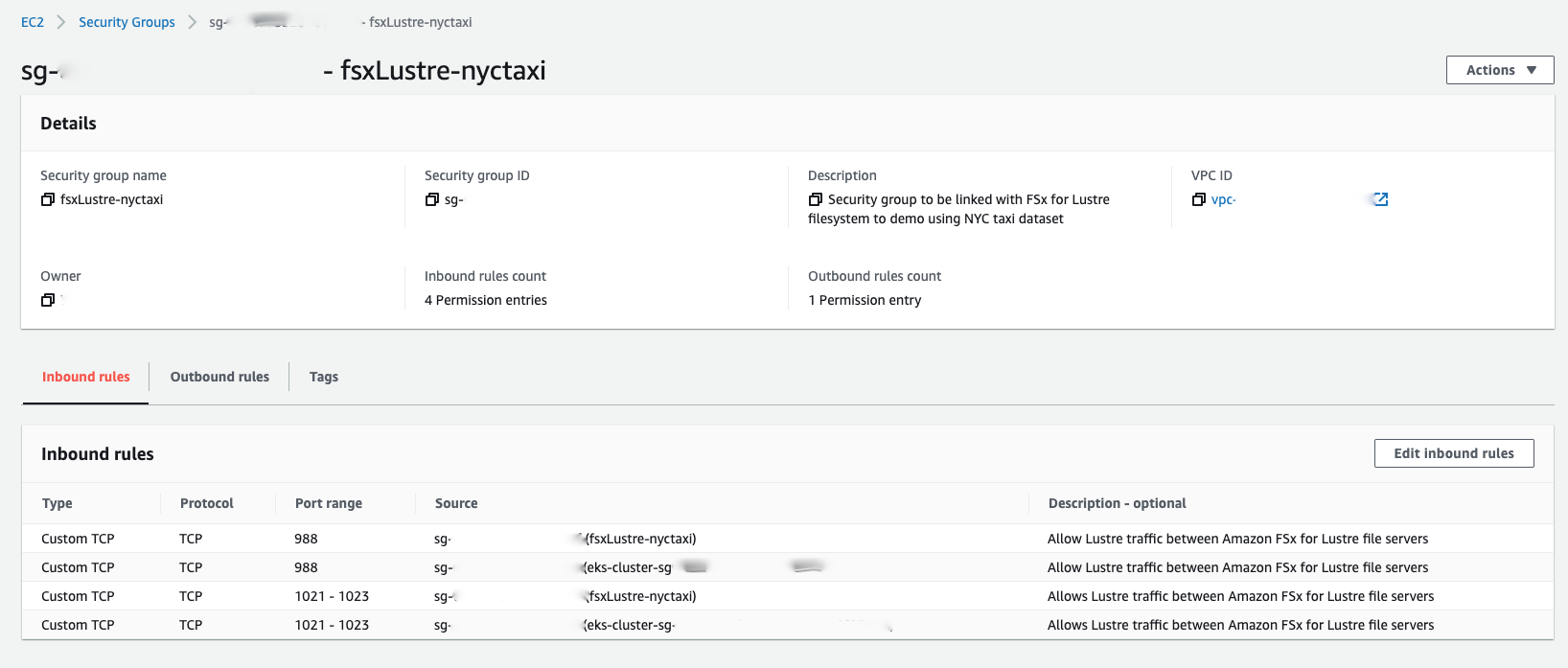
Points to Note:
Security group attached to the EKS worker nodes is given access on port number 988, 1021-1023 in inbound rules.
Security group specified when creating the FSx for Lustre filesystem is given access on port number 988, 1021-1023 in inbound rules.
Fsx for Lustre Provisioning through aws cli
cat fsxLustreConfig.json << EOF
{
"ClientRequestToken": "EMRContainers-fsxLustre-demo",
"FileSystemType": "LUSTRE",
"StorageCapacity": 1200,
"StorageType": "SSD",
"SubnetIds": [
"<subnet-id>"
],
"SecurityGroupIds": [
"<securitygroup-id>"
],
"LustreConfiguration": {
"ImportPath": "s3://<s3 prefix>/",
"ExportPath": "s3://<s3 prefix>/",
"DeploymentType": "PERSISTENT_1",
"AutoImportPolicy": "NEW_CHANGED",
"PerUnitStorageThroughput": 200
}
}
EOF
Run the aws-cli command to create the FSx for Lustre filesystem as below.
aws fsx create-file-system --cli-input-json file:///fsxLustreConfig.json
Response is as below
{
"FileSystem": {
"VpcId": "<vpc id>",
"Tags": [],
"StorageType": "SSD",
"SubnetIds": [
"<subnet-id>"
],
"FileSystemType": "LUSTRE",
"CreationTime": 1603752401.183,
"ResourceARN": "<fsx resource arn>",
"StorageCapacity": 1200,
"LustreConfiguration": {
"CopyTagsToBackups": false,
"WeeklyMaintenanceStartTime": "7:11:30",
"DataRepositoryConfiguration": {
"ImportPath": "s3://<s3 prefix>",
"AutoImportPolicy": "NEW_CHANGED",
"ImportedFileChunkSize": 1024,
"Lifecycle": "CREATING",
"ExportPath": "s3://<s3 prefix>/"
},
"DeploymentType": "PERSISTENT_1",
"PerUnitStorageThroughput": 200,
"MountName": "mvmxtbmv"
},
"FileSystemId": "<filesystem id>",
"DNSName": "<filesystem id>.fsx.<region>.amazonaws.com",
"KmsKeyId": "arn:aws:kms:<region>:<account>:key/<key id>",
"OwnerId": "<account>",
"Lifecycle": "CREATING"
}
}
EKS admin tasks¶
- Attach IAM policy to EKS worker node IAM role to enable access to FSx for Lustre - Mount FSx for Lustre on EKS and Create a Security Group for FSx for Lustre
- Install the FSx CSI Driver in EKS
- Configure Storage Class for FSx for Lustre
- Configure Persistent Volume and Persistent Volume Claim for FSx for Lustre
FSx for Lustre file system is created as described above -Provision a FSx for Lustre cluster
Once provisioned, a persistent volume - as specified below is created with a direct (hard-coded) reference to the created lustre file system. A Persistent Volume claim for this persistent volume will always use the same file system.
cat >fsxLustre-static-pv.yaml <<EOF
apiVersion: v1
kind: PersistentVolume
metadata:
name: fsx-pv
spec:
capacity:
storage: 1200Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
mountOptions:
- flock
persistentVolumeReclaimPolicy: Recycle
csi:
driver: fsx.csi.aws.com
volumeHandle: <filesystem id>
volumeAttributes:
dnsname: <filesystem id>.fsx.<region>.amazonaws.com
mountname: mvmxtbmv
EOF
kubectl apply -f fsxLustre-static-pv.yaml
Now, a Persistent Volume Claim (PVC) needs to be created that references PV created above.
cat >fsxLustre-static-pvc.yaml <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-claim
namespace: ns1
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 1200Gi
volumeName: fsx-pv
EOF
kubectl apply -f fsxLustre-static-pvc.yaml -n <namespace registered with EMR on EKS Virtual Cluster>
Spark Developer Tasks¶
Now spark applications can use fsx-claim in their spark application config to mount the FSx for Lustre filesystem to driver and executor container volumes.
cat >spark-python-in-s3-fsx.json <<EOF
{
"name": "spark-python-in-s3-fsx",
"virtualClusterId": "<virtual-cluster-id>",
"executionRoleArn": "<execution-role-arn>",
"releaseLabel": "emr-6.2.0-latest",
"jobDriver": {
"sparkSubmitJobDriver": {
"entryPoint": "s3://<s3 prefix>/trip-count-repartition-fsx.py",
"sparkSubmitParameters": "--conf spark.driver.cores=5 --conf spark.executor.memory=20G --conf spark.driver.memory=15G --conf spark.executor.cores=6"
}
},
"configurationOverrides": {
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.kubernetes.driver.volumes.persistentVolumeClaim.sparkdata.options.claimName":"fsx-claim",
"spark.kubernetes.driver.volumes.persistentVolumeClaim.sparkdata.mount.path":"/var/data/",
"spark.kubernetes.driver.volumes.persistentVolumeClaim.sparkdata.mount.readOnly":"false",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.sparkdata.options.claimName":"fsx-claim",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.sparkdata.mount.path":"/var/data/",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.sparkdata.mount.readOnly":"false"
}
}
],
"monitoringConfiguration": {
"cloudWatchMonitoringConfiguration": {
"logGroupName": "/emr-containers/jobs",
"logStreamNamePrefix": "demo"
},
"s3MonitoringConfiguration": {
"logUri": "s3://joblogs"
}
}
}
}
EOF
aws emr-containers start-job-run --cli-input-json file:///Spark-Python-in-s3-fsx.json
Expected Behavior:
All spark jobs that are run with persistent volume claims as fsx-claim will mount to the statically created FSx for Lustre file system.
Use case:
- A data pipeline consisting of 10 spark applications can all be mounted to the statically created FSx for Lustre file system and can write the intermediate output to a particular folder. The next spark job in the data pipeline that is dependent on this data can read from FSx for Lustre. Data that needs to be persisted beyond the scope of the data pipeline can be exported to S3 by creating data repository tasks
- Data that is used often by multiple spark applications can also be stored in FSx for Lustre for improved performance.
Dynamic Provisioning¶
A FSx for Lustre file system can be provisioned on-demand. A Storage-class resource is created and that provisions FSx for Lustre file system dynamically. A PVC is created and refers to the storage class resource that was created. Whenever a pod refers to the PVC, the storage class invokes the FSx for Lustre Container Storage Interface (CSI) to provision a Lustre file system on the fly dynamically. In this model, FSx for Lustre of type Scratch File Systems is provisioned.
EKS Admin Tasks¶
- Attach IAM policy to EKS worker node IAM role to enable access to FSx for Lustre - Mount FSx for Lustre on EKS and Create a Security Group for FSx for Lustre
- Install the FSx CSI Driver in EKS
- Configure Storage Class for FSx for Lustre
- Configure Persistent Volume Claim(
fsx-dynamic-claim) for FSx for Lustre.
Create PVC for dynamic provisioning with fsx-sc storage class.
cat >fsx-dynamic-claim.yaml <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-dynamic-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: fsx-sc
resources:
requests:
storage: 3600Gi
EOF
kubectl apply -f fsx-dynamic-pvc.yaml -n <namespace registered with EMR on EKS Virtual Cluster>
Spark Developer Tasks¶
cat >spark-python-in-s3-fsx-dynamic.json << EOF
{
"name": "spark-python-in-s3-fsx-dynamic",
"virtualClusterId": "<virtual-cluster-id>",
"executionRoleArn": "<execution-role-arn>",
"releaseLabel": "emr-6.2.0-latest",
"jobDriver": {
"sparkSubmitJobDriver": {
"entryPoint": "s3://<s3 prefix>/trip-count-repartition-fsx.py",
"sparkSubmitParameters": "--conf spark.driver.cores=5 --conf spark.kubernetes.pyspark.pythonVersion=3 --conf spark.executor.memory=20G --conf spark.driver.memory=15G --conf spark.executor.cores=6 --conf spark.sql.shuffle.partitions=1000"
}
},
"configurationOverrides": {
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.local.dir":"/var/spark/spill/",
"spark.kubernetes.driver.volumes.persistentVolumeClaim.sparkdata.options.claimName":"fsx-claim",
"spark.kubernetes.driver.volumes.persistentVolumeClaim.sparkdata.mount.path":"/var/data/",
"spark.kubernetes.driver.volumes.persistentVolumeClaim.sparkdata.mount.readOnly":"false",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.sparkdata.options.claimName":"fsx-claim",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.sparkdata.mount.path":"/var/data/",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.sparkdata.mount.readOnly":"false",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.spark-local-dir-spill.options.claimName":"fsx-dynamic-claim",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.spark-local-dir-spill.mount.path":"/var/spark/spill/",
"spark.kubernetes.executor.volumes.persistentVolumeClaim.spark-local-dir-spill.mount.readOnly":"false"
}
}
],
"monitoringConfiguration": {
"cloudWatchMonitoringConfiguration": {
"logGroupName": "/emr-containers/jobs",
"logStreamNamePrefix": "demo"
},
"s3MonitoringConfiguration": {
"logUri": "s3://joblogs"
}
}
}
}
EOF
aws emr-containers start-job-run --cli-input-json file:///Spark-Python-in-s3-fsx-dynamic.json
Expected Result:
Statically provisioned FSx for Lustre is mounted to /var/data/ as before for the driver pod.
For all the executors a SCRATCH 1 deployment type FSx for Lustre is provisioned on the fly dynamically by the Storage class that was created. There will be a latency before the first executor can start running - because the Lustre has to be created. Once it is created the same Lustre file system is mounted to all the executors.
Also note - "spark.local.dir":"/var/spark/spill/" is used to force executor to use this folder mounted to Lustre for all spill and shuffle data. Once the spark job is completed, the Lustre file system is deleted or retained based on the PVC configuration.
This dynamically created Lustre file system is mapped to a S3 path like the statically created filesystem.
FSx-csi user guide