Data Lake
Note: This documentation is also available in a rendered format here.
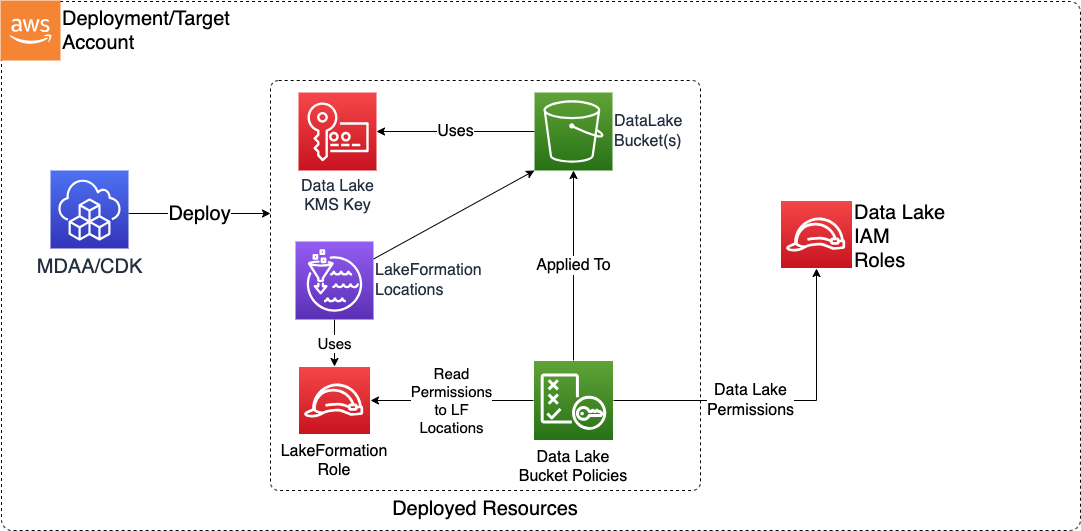
Deploys a secure S3-based data lake with KMS encryption, versioned buckets, prefix-level access policies, S3 inventory, lifecycle rules, Lake Formation location registrations, and Glue catalog databases. Common scenarios include building a centralized data repository for analytics and ML workloads, establishing governed data zones (raw, curated, transformed) for ETL pipelines, or providing a shared storage layer for cross-team data access.
Deployed Resources
This module deploys and integrates the following resources:
Data Lake KMS Key - Customer-managed KMS key used to encrypt all Data Lake resources which support encryption at rest.
Data Lake S3 Buckets - S3 buckets forming the persistence basis of the Data Lake, with versioning, prefix-level access policies, and optional S3 Inventory and Lifecycle rules.
S3 Lifecycle Rules - A set of lifecycle rule configurations which can be applied across data lake buckets.
Glue Utility Database - Glue catalog database for bucket utility tables such as S3 inventory.
Lake Formation Locations - Lake Formation resource registrations for S3 bucket prefixes, enabling governed data access.
Lake Formation Role - IAM role assumed by Lake Formation for accessing registered data lake locations.
Related Modules
- Athena Workgroup — Deploy Athena workgroups for querying data stored in data lake buckets
- Lake Formation Settings — Configure account-level Lake Formation admin roles required for data lake location registrations
- Lake Formation Access Control — Manage fine-grained Lake Formation grants on data lake databases and tables
- Glue Catalog Settings — Configure Glue Catalog encryption and cross-account access for data lake metadata
- Roles — Create IAM roles that can be referenced as data admin, read, write, or super roles on data lake buckets
- Audit — Configure S3 Inventory from data lake buckets into the audit bucket for compliance reporting
- Macie Session — Enable Macie sensitive data discovery on data lake buckets
- DataOps Project — DataOps projects can reference data lake buckets as output targets for ETL jobs
- M2M API — Expose data lake buckets via a secure REST API for programmatic machine-to-machine access
Security/Compliance Details
This module is designed in alignment with MDAA security/compliance principles and CDK nag rulesets. Additional review is recommended prior to production deployment, ensuring organization-specific compliance requirements are met.
- Encryption at Rest:
- All buckets encrypted with customer-managed KMS key
- BucketKey feature minimizes KMS API calls during high-volume operations
- Exclusive KMS key usage enforced by default via bucket policy
- Key usage access granted to all data lake roles via key policy
- Encrypt access granted to S3 service for S3 Inventory writes
- Encryption in Transit:
- SSL enforced on all bucket access via bucket policy
- Least Privilege:
- Prefix-level access policies (read/write/super) injected into bucket policies
- Default-deny bucket policy blocks any role not explicitly specified in config
- Separation of Duties:
- Three access tiers (read, write, super) at prefix level
- Only super user roles can permanently delete object versions
- Write access creates delete markers only
- Bucket versioning enabled by default
- Data Governance:
- Lake Formation location registrations for governed data access
- Glue catalog databases for metadata management
Configuration
MDAA Config
Add the following snippet to your mdaa.yaml under the modules: section of a domain/env in order to use this module:
datalake: # Module Name can be customized
module_path: '@aws-mdaa/datalake' # Must match module NPM package name
module_configs:
- ./datalake.yaml # Filename/path can be customized
Module Config Samples and Variants
Copy the contents of the relevant sample config below into the ./datalake.yaml file referenced in the MDAA config snippet above.
Minimal Configuration
Deploys a three-zone data lake (raw, standardized, curated) with a single admin role and root-level access policy. Start here for a quick data lake deployment before adding lifecycle rules, Lake Formation registrations, or fine-grained access tiers.
# Contents available via above link
# Minimal config for the Data Lake module.
# Deploys a three-zone data lake (raw, standardized, curated) with
# a single admin role and root-level access policy.
# See CONFIGURATION.md for role reference options (name, arn, id).
# Logical role mappings used throughout the config.
roles:
DataAdmin:
- arn: arn:{{partition}}:iam::{{account}}:role/Admin
# Named access policies defining role-based permissions per S3 prefix.
accessPolicies:
Root:
rule:
prefix: /
ReadWriteSuperRoles:
- DataAdmin
# Data lake bucket definitions — one per zone.
buckets:
raw:
accessPolicies:
- Root
standardized:
accessPolicies:
- Root
curated:
accessPolicies:
- Root
Comprehensive Configuration
Deploys a three-zone data lake (raw, standardized, curated) with role-based access policies (admin/user/engineer), lifecycle configurations with tiered storage transitions, S3 inventories, LakeFormation locations, and EventBridge notifications. Use this as a reference when you need full control over bucket layout, access tiers, data lifecycle, and governance integration.
sample-config-comprehensive.yaml
# Contents available via above link
# Comprehensive config for the Data Lake module.
# Exercises all schema properties including optional features.
# Deploys a three-zone data lake (raw, standardized, curated) with
# role-based access policies (admin/user/engineer), lifecycle
# configurations with tiered storage transitions, S3 inventories,
# LakeFormation locations, and EventBridge notifications.
# See CONFIGURATION.md for role reference options (name, arn, id).
# Logical role mappings. Each key is a logical role name used
# throughout the config. Values are lists of physical role references.
# Roles can be referenced by name (auto-expanded to ARN), by explicit ARN,
# by unique ID, by SSM parameter, or as SSO-managed roles.
roles:
DataAdmin:
# Role by ARN
- arn: arn:{{partition}}:iam::{{account}}:role/Admin
# Role by name (auto-expanded to ARN at deploy time)
- name: Admin
# Role by unique ID (use when stable references are a security
# requirement — IDs don't change when roles are recreated)
- id: AROA1234567890
DataUser:
# Role by unique ID via SSM parameter
- id: ssm:/sample-org/instance1/generated-role/test-role/id
# Role by ARN via SSM parameter
- arn: ssm:/sample-org/instance1/generated-role/data-scientist/arn
# Role by MDAA-generated role ID
- id: generated-role-id:test-role
# Role by MDAA-generated role ID
- id: generated-role-id:data-scientist
# SSO-managed role (resolved from IAM Identity Center)
- name: data_scientist
sso: true
DataEngineer:
# Role by ARN
- arn: arn:{{partition}}:iam::{{account}}:role/DataEngineer
# Named access policies defining role-based permissions per S3
# prefix. Policies are referenced by name in bucket configurations.
accessPolicies:
Root: # A friendly name for the access policy
rule:
# S3 prefix path where this access rule applies (e.g., '/data', '/').
prefix: /
# (Optional) Role names granted superuser access including permanent version deletion.
ReadWriteSuperRoles:
- DataAdmin
Data: # A friendly name for the access policy
rule:
prefix: /data
# (Optional) Role names granted read-only access to this prefix.
ReadRoles:
- DataUser
# (Optional) Role names granted read-write access to this prefix.
# Write access creates delete markers but cannot permanently delete versions.
ReadWriteRoles:
- DataEngineer
# (Optional) Named lifecycle configurations containing sets of
# lifecycle rules. Referenced by name in bucket configurations.
lifecycleConfigurations:
SampleConfiguration1: # A friendly name for life cycle transition rules configuration.
SampleRule1:
# Whether this lifecycle rule is active.
Status: Enabled
# (Optional) S3 prefix filter restricting which objects this rule applies to.
Prefix: test_prefix
# (Optional) Minimum object size (bytes) for rule application.
ObjectSizeGreaterThan: 500
# (Optional) Maximum object size (bytes) for rule application.
ObjectSizeLessThan: 10000
# (Optional) Days after which incomplete multipart uploads are automatically aborted.
AbortIncompleteMultipartUploadAfter: 2
# (Optional) Storage class transitions for current object versions.
Transitions:
# Number of days after object creation (or becoming noncurrent) to trigger the transition.
- Days: 30
# Target S3 storage class for the transition.
StorageClass: STANDARD_IA
- Days: 60
StorageClass: GLACIER_IR
- Days: 150
StorageClass: GLACIER
- Days: 240
StorageClass: DEEP_ARCHIVE
# (Optional) Days after creation when current object versions expire (are deleted). Cannot be
# set together with ExpiredObjectDeleteMarker.
ExpirationDays: 270
# ExpiredObjectDeleteMarker: True # Permanently delete expired objects. Cannot be set if ExpirationDays is set
# (Optional) Storage class transitions for noncurrent (previous) object versions.
NoncurrentVersionTransitions:
- Days: 30
StorageClass: STANDARD_IA
# (Optional) Number of newer noncurrent versions to retain before applying this
# transition.
NewerNoncurrentVersions: 1
- Days: 60
StorageClass: GLACIER_IR
NewerNoncurrentVersions: 2
- Days: 150
StorageClass: GLACIER
NewerNoncurrentVersions: 3
- Days: 240
StorageClass: DEEP_ARCHIVE
NewerNoncurrentVersions: 4
# (Optional) Days after which noncurrent versions expire (are permanently deleted).
NoncurrentVersionExpirationDays: 270
# (Optional) Number of noncurrent versions to retain before applying expiration.
NoncurrentVersionsToRetain: 5
SampleRule2:
Status: Enabled
Prefix: test_prefix
ObjectSizeGreaterThan: 500
ObjectSizeLessThan: 10000
AbortIncompleteMultipartUploadAfter: 2
Transitions:
- Days: 30
StorageClass: STANDARD_IA
- Days: 60
StorageClass: GLACIER_IR
- Days: 150
StorageClass: GLACIER
- Days: 240
StorageClass: DEEP_ARCHIVE
# (Optional) Permanently remove expired object delete markers to reduce storage overhead.
# Cannot be set together with ExpirationDays.
ExpiredObjectDeleteMarker: True
NoncurrentVersionTransitions:
- Days: 30
StorageClass: STANDARD_IA
NewerNoncurrentVersions: 1
- Days: 60
StorageClass: GLACIER_IR
NewerNoncurrentVersions: 2
- Days: 150
StorageClass: GLACIER
NewerNoncurrentVersions: 3
- Days: 240
StorageClass: DEEP_ARCHIVE
NewerNoncurrentVersions: 4
NoncurrentVersionExpirationDays: 270
NoncurrentVersionsToRetain: 5
SampleConfiguration2: # A friendly name for life cycle transition rules configuration.
SampleRule1:
Status: Enabled
Prefix: test_prefix
Transitions:
- Days: 30
StorageClass: STANDARD_IA
SampleRule2:
Status: Enabled
Prefix: test_prefix
NoncurrentVersionTransitions:
- Days: 30
StorageClass: STANDARD_IA
NewerNoncurrentVersions: 1
# Data lake bucket definitions keyed by zone name (e.g., 'raw',
# 'transformed', 'curated'). Each bucket gets its own S3 bucket
# with the specified access policies and features.
buckets:
raw:
# (Optional) Deny access to any role not explicitly listed in access policies.
# (default: true)
defaultDeny: false
#enableEventBridgeNotifications: true
# (Optional) Create folder placeholder objects for each access policy prefix.
# (default: true)
createFolderSkeleton: false
# (Optional) S3 inventory configurations for automated bucket content reporting. Each entry
# generates inventory data for the specified prefix.
#Inventory data will be written for each listed name/prefix under /inventory/<name>
inventories:
all-data:
# S3 prefix to include in the inventory report.
prefix: data
# Inventory with cross-account destination fields
cross-account-inventory:
# S3 prefix to include in the inventory report.
prefix: data/reports
# (Optional) AWS account ID owning the destination bucket for cross-account inventory delivery.
destinationAccount: '{{context:account-2}}'
# (Optional) Destination bucket for inventory reports. Defaults to the source bucket
# under the /inventory prefix if not specified.
destinationBucket: central-inventory-bucket
# (Optional) S3 prefix within the destination bucket for inventory report storage.
destinationPrefix: datalake/raw
# Access policy names to apply to this bucket. Each name must reference a policy defined in the
# top-level accessPolicies configuration.
accessPolicies:
- Root
- Data
# (Optional) Name of a lifecycle configuration from the top-level lifecycleConfigurations to
# apply to this bucket.
lifecycleConfiguration: SampleConfiguration1
standardized:
# (Optional) Create folder placeholder objects for each access policy prefix.
createFolderSkeleton: true
# (Optional) Enable EventBridge notifications for S3 data events on this bucket.
enableEventBridgeNotifications: true
# (Optional) LakeFormation location registrations for governed access.
lakeFormationLocations:
standardized-data:
prefix: data
accessPolicies:
- Root
- Data
lifecycleConfiguration: SampleConfiguration2
curated:
createFolderSkeleton: true
# (Optional) Enable EventBridge notifications for S3 data events on this bucket.
enableEventBridgeNotifications: true
# (Optional) LakeFormation location registrations for fine-grained access control at specific
# S3 prefixes within this bucket.
lakeFormationLocations:
read-data:
# S3 prefix within the bucket to register with LakeFormation.
prefix: data
read-write-data:
prefix: data
# (Optional) Grant write access to the LakeFormation role for this location. (default: false)
write: true
accessPolicies:
- Root
- Data
lifecycleConfiguration: SampleConfiguration2
# (Optional) Cross-origin resource sharing rules for this bucket.
# Required when web browsers or AWS services need cross-origin access.
corsRules:
# CORS rule for SageMaker Ground Truth labeling workflows
- id: sagemaker-ground-truth
# Origins allowed to make cross-origin requests to the bucket.
allowedOrigins:
- 'https://sagemaker.*.amazonaws.com'
# HTTP methods allowed for cross-origin requests.
# (enum: GET, PUT, HEAD, POST, DELETE)
allowedMethods:
- GET
- PUT
- POST
# (Optional) Headers allowed in cross-origin requests.
allowedHeaders:
- '*'
# (Optional) Response headers exposed to the browser.
exposedHeaders:
- ETag
# (Optional) Time in seconds the browser caches the preflight response.
maxAge: 3000
# (Optional) Enable S3 Storage Lens for storage analytics
# covering all buckets defined in this app's config.
storageLensEnabled: true