Basic Crawler
This Basic Crawler sample blueprint illustrates how to create a crawler for discovering new data on an S3 data lake.
This blueprint may be suitable when:
- A new dataset has been loaded into an S3 Data Lake and new tables need to be created.
- New data has been loaded to an existing dataset in S3 and table partitions need to be updated.
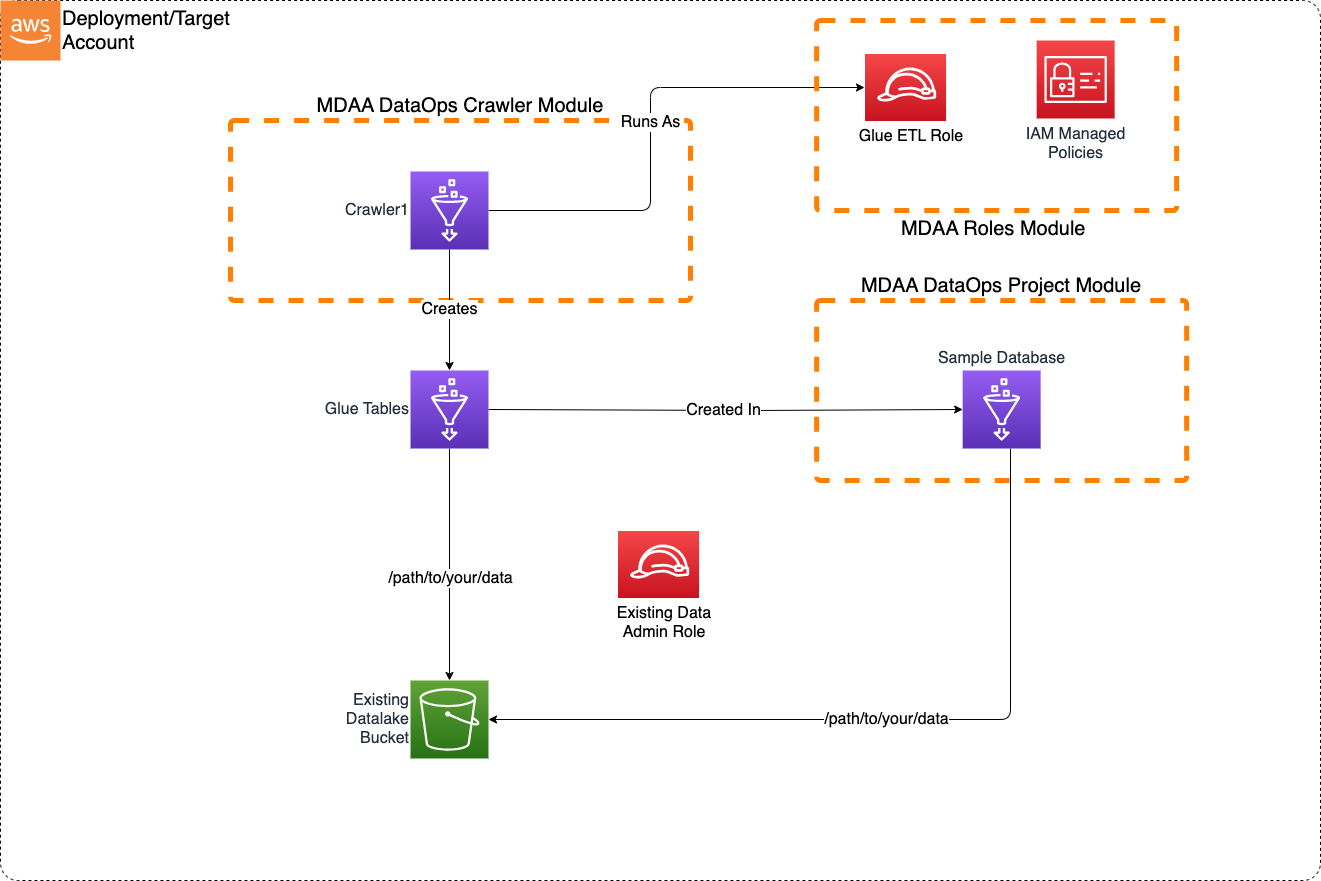
Usage Instructions
The following instructions assume you have already deployed your Data Lake (possibly using MDAA). Note: Additional configuration may be required if LakeFormation is in use on the data lake. These instructions assume the blueprint will be deployed independently of any existing MDAA deployment. Alternatively, these blueprint configs can be merged into an existing MDAA deployment.
-
Deploy sample configurations into the specified directory structure (or obtain from the MDAA repo under
sample_blueprints/basic_crawler). -
Edit the
mdaa.yamlto specify an organization name to replace<unique-org-name>. This must be a globally unique name, as it is used in the naming of all deployed resources, some of which are globally named (such as S3 buckets). -
Edit the
mdaa.yamlto specify a project name which is unique within your organization, replacing<your-project-name>. -
Edit the
mdaa.yamlto specify appropriate context values for your environment. -
Ensure you are authenticated to your target AWS account.
-
Optionally, run
<path_to_mdaa_repo>/bin/mdaa lsfrom the directory containingmdaa.yamlto understand what stacks will be deployed. -
Optionally, run
<path_to_mdaa_repo>/bin/mdaa synthfrom the directory containingmdaa.yamland review the produced templates. -
Run
<path_to_mdaa_repo>/bin/mdaa deployfrom the directory containingmdaa.yamlto deploy all modules. -
Before running the crawler, you will need to provide the generated
glue-etlrole with access to your datalake bucket. Additionally, to test the crawler, you can load data from./sample_datainto the datalake.
Additional MDAA deployment commands/procedures can be reviewed in DEPLOYMENT.
Configurations
The sample configurations for this blueprint are provided below. They are also available under sample_blueprints/basic_crawler within the MDAA repo.
Config Directory Structure
basic_crawler
│ mdaa.yaml
│ tags.yaml
│
└───basic_crawler
└───roles.yaml
└───project.yaml
└───crawler.yaml
mdaa.yaml
This configuration specifies the global, domain, env, and module configurations required to configure and deploy this sample architecture.
Note - Before deployment, populate the mdaa.yaml with appropriate organization and context values for your environment
# Contents available in mdaa.yaml
# All resources will be deployed to the default region specified in the environment or AWS configurations.
# Can optional specify a specific AWS Region Name.
region: default
# One or more tag files containing tags which will be applied to all deployed resources
tag_configs:
- ./tags.yaml
## Pre-Deployment Instructions
# TODO: Set an appropriate, unique organization name, likely matching the org name used in other MDAA configs.
# Failure to do so may resulting in global naming conflicts.
organization: <unique-org-name>
# One or more domains may be specified. Domain name will be incorporated by default naming implementation
# to prefix all resource names.
domains:
# TODO: Set an appropriate project name. This project name should be unique within the organzation.
<your-project-name>:
# One or more environments may be specified, typically along the lines of 'dev', 'test', and/or 'prod'
environments:
# The environment name will be incorporated into resource name by the default naming implementation.
dev:
# The target deployment account can be specified per environment.
# If 'default' or not specified, the account configured in the environment will be assumed.
account: default
#TODO: Set context values appropriate to your env
context:
# The arn of a role which will be provided admin privileges to dataops resources
data_admin_role_arn : <your-data-admin-role-arn> #TODO
# The name of the datalake S3 bucket where the data to be crawled is stored
datalake_bucket_name: <your-datalake-bucket-name> #TODO
# The prefix on the datalake S3 bucket where the data to be crawled is stored
datalake_bucket_prefix: <your/path/to/data> #TODO
# The arn of the KMS key used to encrypt the datalake bucket
datalake_kms_arn: <your-datalake-kms-key-arn> #TODO
# The arn of the KMS key used to encrypt the Glue Catalog
glue_catalog_kms_arn: <your-datalake-kms-key-arn> #TODO
# The list of modules which will be deployed. A module points to a specific MDAA CDK App, and
# specifies a deployment configuration file if required.
modules:
# This module will create all of the roles required for the crawler, a
roles:
module_path: "@aws-mdaa/roles"
module_configs:
- ./basic_crawler/roles.yaml
# This module will create DataOps Project resources which can be shared
# across multiple DataOps modules
project:
module_path: "@aws-mdaa/dataops-project"
module_configs:
- ./basic_crawler/project.yaml
crawler:
module_path: "@aws-mdaa/dataops-crawler"
module_configs:
- ./basic_crawler/crawler.yaml
tags.yaml
This configuration specifies the tags to be applied to all deployed resources.
basic_crawler/roles.yaml
This configuration will be used by the MDAA Roles module to deploy IAM roles and Managed Policies required for this sample architecture.
# Contents available in basic_crawler/roles.yaml
generatePolicies:
GlueJobPolicy:
policyDocument:
Statement:
- SID: GlueCloudwatch
Effect: Allow
Resource:
- "arn:{{partition}}:logs:{{region}}:{{account}}:log-group:/aws-glue/*"
Action:
- logs:CreateLogStream
- logs:AssociateKmsKey
- logs:CreateLogGroup
- logs:PutLogEvents
suppressions:
- id: "AwsSolutions-IAM5"
reason: "Glue log group name not known at deployment time."
# The list of roles which will be generated
generateRoles:
glue-etl:
trustedPrincipal: service:glue.amazonaws.com
# A list of AWS managed policies which will be added to the role
awsManagedPolicies:
- service-role/AWSGlueServiceRole
generatedPolicies:
- GlueJobPolicy
suppressions:
- id: "AwsSolutions-IAM4"
reason: "AWSGlueServiceRole approved for usage"
basic_crawler/project.yaml
This configuration will create a DataOps Project which can be used to support a wide variety of data ops activities. Specifically, this configuration will create a number of Glue Catalog databases and apply fine-grained access control to these using basic.
# Contents available in basic_crawler/project.yaml
# Arns for IAM roles which will be provided to the projects's resources (IE bucket)
dataAdminRoles:
# This is an arn which will be resolved first to a role ID for inclusion in the bucket policy.
# Note that this resolution will require iam:GetRole against this role arn for the role executing CDK.
- arn: "{{context:data_admin_role_arn}}"
# List of roles which will be used to execute dataops processes using project resources
projectExecutionRoles:
- id: generated-role-id:glue-etl
s3OutputKmsKeyArn: "{{context:datalake_kms_arn}}"
glueCatalogKmsKeyArn: "{{context:glue_catalog_kms_arn}}"
# List of Databases to create within the project.
databases:
# This database will be used to illustrate access grants
# using LakeFormation.
sample-database:
description: Sample Database
# The data lake S3 bucket and prefix location where the database data is stored.
# Project execution roles will be granted access to create Glue tables
# which point to this location.
locationBucketName: "{{context:datalake_bucket_name}}"
locationPrefix: "{{context:datalake_bucket_prefix}}"
basic_crawler/crawler.yaml
This configuration will create Glue crawlers using the DataOps Crawler module.
# Contents available in basic_crawler/crawler.yaml
# The name of the dataops project this crawler will be created within.
# The dataops project name is the MDAA module name for the project.
projectName: project
crawlers:
crawler1:
executionRoleArn: generated-role-arn:glue-etl
# (required) Reference back to the database name in the 'databases:' section of the crawler.yaml
databaseName: project:databaseName/sample-database
# (required) Description of the crawler
description: Example for a Crawler
# (required) At least one target definition. See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-glue-crawler-targets.html
targets:
# (at least one). S3 Target. See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-glue-crawler-s3target.html
s3Targets:
- path: s3://{{context:datalake_bucket_name}}/{{context:datalake_bucket_prefix}}