Basic Terraform Data Lake
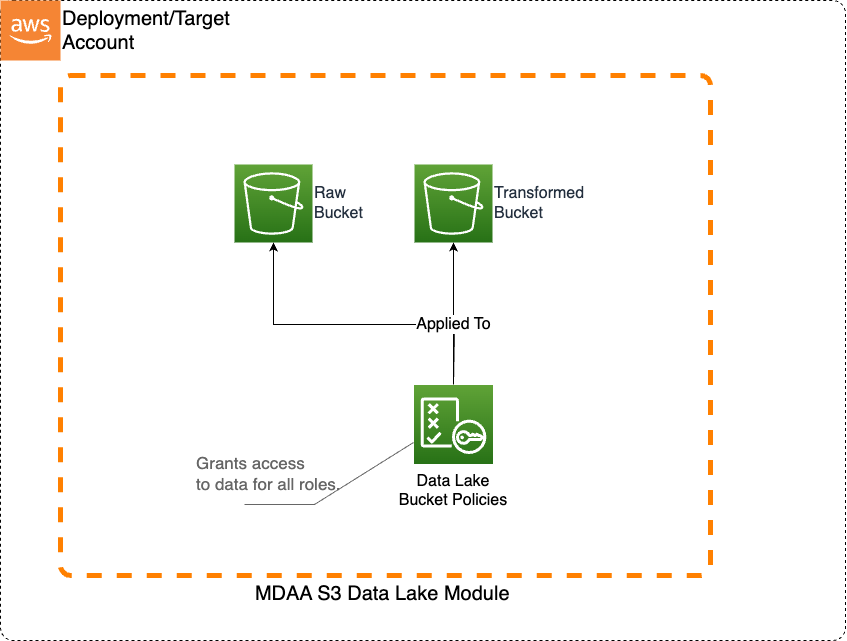
This basic S3 Data Lake sample illustrates how to create an S3 data lake on AWS. Access to the data lake may be granted to IAM and federated principals, and is controlled on a coarse-grained basis only (using S3 bucket policies). This sample uses Terraform module implementations.
This architecture may be suitable when:
- Data is primarily unstructured and will not be consumed via Athena.
- User access to the data lake does not need to be governed by fine-grained access controls.
Deployment Instructions
The following instructions assume you have CDK bootstrapped your target account, and that the MDAA source repo is cloned locally. More predeployment info and procedures are available in PREDEPLOYMENT.
-
Deploy sample configurations into the specified directory structure (or obtain from the MDAA repo under
sample_configs/basic_terraform_datalake). -
Edit the
mdaa.yamlto specify an organization name. This must be a globally unique name, as it is used in the naming of all deployed resources, some of which are globally named (such as S3 buckets). -
If required, edit the
mdaa.yamlto specifycontext:values specific to your environment. -
Ensure you are authenticated to your target AWS account.
-
Optionally, run
<path_to_mdaa_repo>/bin/mdaa lsfrom the directory containingmdaa.yamlto understand what stacks will be deployed. -
Optionally, run
<path_to_mdaa_repo>/bin/mdaa synthfrom the directory containingmdaa.yamland review the produced templates. -
Run
<path_to_mdaa_repo>/bin/mdaa deployfrom the directory containingmdaa.yamlto deploy all modules.
Additional MDAA deployment commands/procedures can be reviewed in DEPLOYMENT.
Configurations
The sample configurations for this architecture are provided below. They are also available under sample_configs/basic_terraform_datalake within the MDAA repo.
Config Directory Structure
mdaa.yaml
This configuration specifies the global, domain, env, and module configurations required to configure and deploy this sample architecture.
Note - Before deployment, populate the mdaa.yaml with appropriate organization and context values for your environment
# Contents available in mdaa.yaml
# All resources will be deployed to the default region specified in the environment or AWS configurations.
# Can optional specify a specific AWS Region Name.
region: <your-aws-region-name>
## Pre-Deployment Instructions
# TODO: Set an appropriate, unique organization name
# Failure to do so may resulting in global naming conflicts.
organization: <your-org-name>
# TODO: If using an S3 Terraform backend, uncomment these lines and set the backend S3 bucket and DynamoDB table names.
# If not configured, local state tracking will be used.
terraform:
override:
terraform:
backend:
s3:
bucket: <your-tf-state-bucket-name>
dynamodb_table: <your-tf-state-lock-ddb-table>
# One or more domains may be specified. Domain name will be incorporated by default naming implementation
# to prefix all resource names.
domains:
# The named of the domain. In this case, we are building a 'shared' domain.
shared:
# One or more environments may be specified, typically along the lines of 'dev', 'test', and/or 'prod'
environments:
# The environment name will be incorporated into resource name by the default naming implementation.
dev:
use_bootstrap: false
# The target deployment account can be specified per environment.
# If 'default' or not specified, the account configured in the environment will be assumed.
account: default
# The list of modules which will be deployed. A module points to a specific MDAA CDK App, and
# specifies a deployment configuration file if required.
modules:
# This module will deploy the S3 data lake buckets.
# Coarse grained access may be granted directly to S3 for certain roles.
glue-catalog:
module_type: tf
module_path: ./glue-catalog/
# This module will deploy the S3 data lake buckets.
# Coarse grained access may be granted directly to S3 for certain roles.
datalake1:
module_type: tf
module_path: ./datalake/
mdaa_compliant: true
datalake/main.tf
This Terraform module will consume the MDAA DataLake TF module to create a datalake.
# Contents available in datalake/main.tf
# Copyright © Amazon.com and Affiliates: This deliverable is considered Developed Content as defined in the AWS Service Terms.
variable "region" {
description = "The region to be deployed to"
type = string
}
variable "org" {
description = "The org name used in the naming convention"
type = string
}
variable "domain" {
description = "The domain name used in the naming convention"
type = string
}
variable "env" {
description = "The env name used in the naming convention"
type = string
}
variable "module_name" {
description = "The module_name name used in the naming convention"
type = string
}
variable "force_destroy" {
description = "If true, the resources will be force destroyed"
type = bool
default = false
}
locals {
# Sample Roles
data_admin_role_arn = "arn:aws:iam::${data.aws_caller_identity.current.account_id}:role/Admin"
data_engineer_role_arn = "arn:aws:iam::${data.aws_caller_identity.current.account_id}:role/DataEngineer"
data_scientist_role_arn = "arn:aws:iam::${data.aws_caller_identity.current.account_id}:role/DataScientist"
}
module "mdaa_datalake" {
# checkov:skip=CKV_TF_1:Ensure Terraform module sources use a commit hash:Not required.
# checkov:skip=CKV_TF_2:Ensure Terraform module sources use a tag with a version number:Not required.
# TODO: Point to the MDAA Terraform Git Repo
# If using Git SSH, be sure to use the git::ssh://<url> syntax. Otherwise TF might download the module, but checkov will fail to.
source = "<your-git-url>//modules/datalake"
force_destroy = var.force_destroy
module_name = var.module_name
bucket_definitions = {
# RAW BUCKET
"raw" = {
base_name = "raw"
access_policies = {
"root" = {
READWRITESUPER = {
role_arns = [local.data_admin_role_arn],
}
}
"data" = {
READ = {
role_arns = [local.data_scientist_role_arn],
}
READWRITE = {
role_arns = [local.data_engineer_role_arn],
}
}
}
}
# CURATED BUCKET
"curated" = {
base_name = "curated"
access_policies = {
"root" = {
READWRITESUPER = {
role_arns = [local.data_admin_role_arn],
},
}
"data-product-A" = {
READWRITE = {
role_arns = [local.data_engineer_role_arn, local.data_scientist_role_arn],
}
}
"data-product-B" = {
READ = {
role_arns = [local.data_scientist_role_arn],
}
READWRITE = {
role_arns = [local.data_engineer_role_arn],
}
}
}
}
}
}
data "aws_caller_identity" "current" {}
# Creates a Data Engineer Athena Workgroup
module "example_workgroup" {
# checkov:skip=CKV_TF_1:Ensure Terraform module sources use a commit hash:Not required.
# checkov:skip=CKV_TF_2:Ensure Terraform module sources use a tag with a version number:Not required.
# TODO: Point to the MDAA Terraform Git Repo
# If using Git SSH, be sure to use the git::ssh://<url> syntax. Otherwise TF might download the module, but checkov will fail to.
source = "<your-git-url>//modules/athena-workgroup"
module_name = var.module_name
base_name = "data-engineer"
force_destroy = var.force_destroy
bytes_scanned_cutoff_per_query = 10000000000
data_admin_role_arn = local.data_admin_role_arn
service_execution_role_arns = [local.data_engineer_role_arn, local.data_scientist_role_arn]
}
glue-catalog/main.tf
This Terraform module will consume the MDAA GlueCatalog TF module to create a datalake.
# Contents available in glue-catalog/main.tf
# Copyright © Amazon.com and Affiliates: This deliverable is considered Developed Content as defined in the AWS Service Terms.
variable "region" {
description = "The region to be deployed to"
type = string
}
variable "org" {
description = "The org name used in the naming convention"
type = string
}
variable "domain" {
description = "The domain name used in the naming convention"
type = string
}
variable "env" {
description = "The env name used in the naming convention"
type = string
}
variable "module_name" {
description = "The module_name name used in the naming convention"
type = string
}
variable "force_destroy" {
description = "If true, the resources will be force destroyed"
type = bool
default = false
}
module "glue-catalog" {
# checkov:skip=CKV_TF_1:Ensure Terraform module sources use a commit hash:Not required.
# checkov:skip=CKV_TF_2:Ensure Terraform module sources use a tag with a version number:Not required.
# TODO: Point to the MDAA Terraform Git Repo
# If using Git SSH, be sure to use the git::ssh://<url> syntax. Otherwise TF might download the module, but checkov will fail to.
source = "<your-git-url>//modules/glue-catalog-setting"
module_name = var.module_name
}