ETL Jobs
Note: This documentation is also available in a rendered format here.
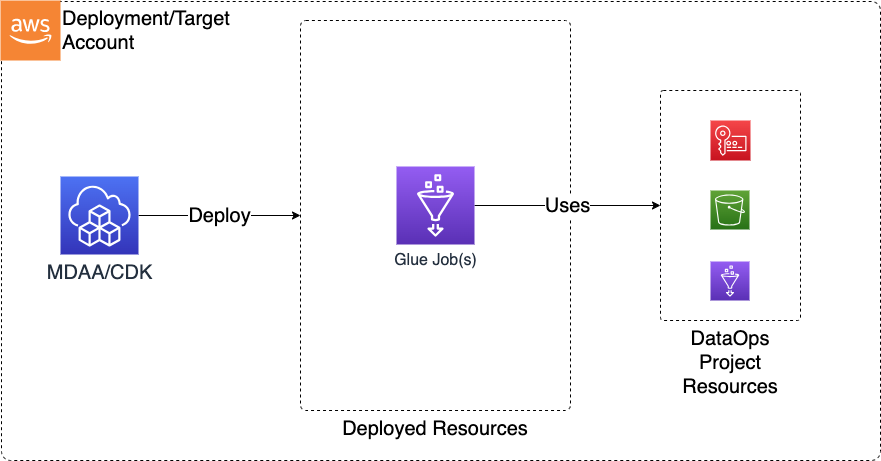
Deploys Glue ETL jobs with automatic script deployment, job templates for config reuse, continuous logging, VPC binding, and project security configuration wiring. Supports Python and Scala runtimes. Use this module when you need to transform, enrich, or move data between sources using Glue Spark or Python shell jobs as part of your data pipeline.
Pre-built Data Quality Script
The module includes a pre-built Glue ETL script for data quality evaluation in the assets/ directory. Reference it using the asset: prefix in scriptLocation and additionalScripts:
dq-main.py — DQ evaluation
Evaluates data quality rulesets against a single table. Supports inline DQDL, S3-stored DQDL, and Glue recommendation rulesets. Optionally publishes results to SageMaker Unified Studio (DataZone). For multi-table fan-out, use dataops-stepfunction-app with a Distributed Map that starts one dq-main.py job run per table.
DqEvaluation:
command:
name: glueetl
scriptLocation: "asset:dq-main.py"
additionalScripts:
- "asset:dq_config.py"
- "asset:smus.py"
Shared utilities
asset:dq_config.py— Configuration utilities. Loads rulesets and source data frames from Glue catalog or connection options.asset:smus.py— SMUS publishing. Posts DQ evaluation results to DataZone viapost_time_series_data_points.
Deployed Resources
This module deploys and integrates the following resources:
Glue Jobs - Glue Jobs will be created for each job specification in the configs
- Automatically configured to use project security config
- Can optionally be VPC bound (via Glue connection)
- Automatically configured to use project bucket as temp location
- Can use job templates to promote reuse/minimize config duplication
Related Modules
- DataOps Project — Deploy the shared project infrastructure (KMS keys, security configs, connections, buckets) that ETL jobs reference
- Crawlers — Deploy crawlers to catalog ETL job output data in the Glue Catalog
- Workflows — Orchestrate ETL jobs and crawlers together in Glue Workflows
- Step Functions — Orchestrate ETL jobs with Step Functions state machines
- Data Quality — Deploy data quality rulesets to validate ETL job output
- Data Lake — ETL jobs can read from and write to data lake S3 buckets
Security/Compliance Details
This module is designed in alignment with MDAA security/compliance principles and CDK nag rulesets. Additional review is recommended prior to production deployment, to assist in meeting organization-specific compliance requirements.
- Encryption at Rest:
- Jobs use project Glue security configuration for encrypting output data, logs, and bookmarks with the project KMS key
- S3 output optionally encrypted with a separate data lake KMS key
- Least Privilege:
- Execution roles scoped per job
- Project resources referenced via
project:prefix for consistent access control
- Network Isolation:
- Optional VPC binding via Glue connections for accessing data sources in private networks
Configuration
MDAA Config
Add the following snippet to your mdaa.yaml under the modules: section of a domain/env in order to use this module:
dataops-job: # Module Name can be customized
module_path: '@aws-mdaa/dataops-job' # Must match module NPM package name
module_configs:
- ./dataops-job.yaml # Filename/path can be customized
Module Config Samples and Variants
Copy the contents of the relevant sample config below into the ./dataops-job.yaml file referenced in the MDAA config snippet above.
Minimal Configuration
Deploys a single Glue ETL job with project autowiring. Start here for a basic ETL job within an existing DataOps project.
# Contents available via above link
# Minimal DataOps Job module configuration.
# Deploys a single Glue ETL job with project autowiring.
# (Optional) DataOps project name for job resource autowiring.
projectName: dataops-project-test
# Map of job names to Glue job definitions.
jobs:
MyJob:
# IAM role ARN for Glue job execution permissions.
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# Job command configuration.
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# (Optional) Python version. (enum: 2, 3)
pythonVersion: '3'
# Relative path to the Glue script.
scriptLocation: ./src/glue/python/job.py
# Job description.
description: Minimal Glue ETL job
# (Optional) Glue runtime version.
glueVersion: '2.0'
# (Optional) Number of capacity units.
allocatedCapacity: 2
Comprehensive Configuration
Demonstrates Glue ETL and Python shell jobs with templates, job bookmarks, connections, and extra libraries, all wired to a DataOps project. Start here when evaluating all available options for job types, templates, connections, and library configurations.
sample-config-comprehensive.yaml
# Contents available via above link
# Sample config for the DataOps Job module - project variant.
# Demonstrates Glue ETL and Python shell jobs with templates, job
# bookmarks, connections, and extra libraries, all wired to a
# DataOps project.
# (Optional) DataOps project name for job resource autowiring
# (databases, roles, security).
projectName: dataops-project-test
# (Optional) SNS topic ARN for job notifications and workflow alerts.
# Auto-resolved from project when projectName is set.
notificationTopicArn: arn:{{partition}}:sns:{{region}}:{{account}}:test-topic
# (Optional) Reusable job templates that can be inherited by job
# definitions via the template field. Template properties are
# deep-merged with job-specific overrides.
templates:
ExamplePythonTemplate:
# IAM role ARN for Glue job execution permissions.
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# Job command configuration defining script and runtime
# environment.
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# (Optional) Python version for job runtime. (enum: 2, 3)
pythonVersion: '3'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/python/job.py
# Job description for documentation and management.
description: Example of a Glue Job using an inline script
# (Optional) Connection names for database and external system
# access.
connections:
- project:connections/connectionVpc
# (Optional) Default arguments passed to the job at runtime.
defaultArguments:
--job-bookmark-option: job-bookmark-enable
# (Optional) Execution properties including maximum concurrent
# runs.
executionProperty:
maxConcurrentRuns: 1
# (Optional) Glue runtime version for the job.
glueVersion: '2.0'
# (Optional) Maximum DPU capacity for the job.
# Note: Use maxCapacity OR workerType+numberOfWorkers, not both.
maxCapacity: 1
# (Optional) Maximum retry count before job failure.
maxRetries: 3
# (Optional) Notification settings for job monitoring and
# alerting.
notificationProperty:
# After a job run starts, minutes to wait before sending a
# delay notification.
notifyDelayAfter: 1
# (Optional) Job timeout in minutes.
timeout: 60
ExampleScalaTemplate:
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# (Optional) Default arguments passed to the job at runtime.
defaultArguments:
--job-language: scala
# (Optional) Glue runtime version for the job.
glueVersion: '5.0'
# Map of job names to Glue job definitions for ETL processing and
# data transformation.
jobs:
PythonJobOne:
# (Optional) Template name for configuration inheritance.
template: 'ExamplePythonTemplate'
defaultArguments:
--Input: s3://some-bucket/some-location1
# (Optional) Number of capacity units allocated to the job.
allocatedCapacity: 2
# (Optional) Continuous logging configuration for real-time
# monitoring.
continuousLogging:
# CloudWatch log group retention in days. Allowed:
# 1,3,5,7,14,30,60,90,120,150,180,365,400,545,731,1827,3653,0.
logGroupRetentionDays: 3
PythonJobTwo:
template: 'ExamplePythonTemplate'
defaultArguments:
--Input: s3://some-bucket/some-location2
--enable-spark-ui: 'true'
--spark-event-logs-path: s3://some-bucket/spark-event-logs-path/JobTwo/
allocatedCapacity: 20
# (Optional) Relative paths to additional Python scripts for
# the job.
additionalScripts:
- ./src/glue/python/helper_etl.py
- ./src/glue/python/utils/core.py
# (Optional) Relative paths to additional files for the job.
additionalFiles:
- ./src/glue/scala/extra_file.txt
ScalaJobOne:
template: 'ExampleScalaTemplate'
description: testing
defaultArguments:
--class: some.java.package.App
allocatedCapacity: 2
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/scala/App.scala
# (Optional) Relative paths to additional files for the job.
additionalFiles:
- ./src/glue/scala/extra_file.txt
# (Optional) Relative paths to additional JAR files for the job.
additionalJars:
- ./src/glue/scala/lib/extra.jar
# Python shell job exercising pythonshell command name and
# Python version 2 enum value.
PythonShellJob:
# IAM role ARN for Glue job execution permissions.
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# Job description for documentation and management.
description: Python shell job for lightweight data processing
command:
# Job type. (enum: glueetl, pythonshell)
name: 'pythonshell'
# (Optional) Python version for job runtime. (enum: 2, 3)
pythonVersion: '2'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/python/job.py
# (Optional) Maximum DPU capacity for the job.
# Note: pythonshell jobs use maxCapacity (0.0625 or 1).
maxCapacity: 1
# (Optional) Glue runtime version for the job.
glueVersion: '1.0'
# (Optional) Maximum retry count before job failure.
maxRetries: 0
# (Optional) Job timeout in minutes.
timeout: 30
# Data Quality evaluation job using the pre-built DQ script from DF.
# Use the `asset:` prefix to reference bundled scripts instead of
# providing a local file path.
DqEvaluationJob:
executionRoleArn: some-arn
description: Run Glue Data Quality evaluations with optional SMUS publishing
command:
name: 'glueetl'
# Use asset: prefix to reference the pre-built DQ main script
scriptLocation: "asset:dq-main.py"
glueVersion: '4.0'
numberOfWorkers: 2
workerType: 'G.1X'
timeout: 60
# Deploy the utils package alongside the main script
additionalScripts:
- "asset:dq_config.py"
- "asset:smus.py"
defaultArguments:
--application_opts: '{"table": {"name": "my_table", "source": {"database": "my_db", "table_name": "my_table"}, "rulesets": {"basic": {"type": "dqdl", "value": "Rules = [IsComplete \"id\"]"}}}}'
Standalone Configuration (No Project)
Demonstrates standalone Glue jobs with explicit KMS, bucket, deployment role, and security configuration. Use this when deploying outside of a DataOps project, providing infrastructure references directly.
# Contents available via above link
# Sample config for the DataOps Job module - no-project variant.
# Demonstrates standalone Glue jobs with explicit KMS, bucket,
# deployment role, and security configuration.
# (Optional) KMS key ARN for encrypting DataOps resources and data.
# Auto-resolved from project when projectName is set.
kmsArn: arn:{{partition}}:kms:{{region}}:{{account}}:key/test-key-id
# (Optional) Glue security configuration name for job encryption
# (at rest, in transit, CloudWatch logs). Auto-resolved from project
# when projectName is set.
securityConfigurationName: test-security-config
# (Optional) IAM role ARN for deployment operations and resource
# management. Auto-resolved from project when projectName is set.
deploymentRoleArn: arn:{{partition}}:iam::{{account}}:role/test-deployment-role
# (Optional) S3 bucket name for project storage (scripts, artifacts,
# temp files). Auto-resolved from project when projectName is set.
bucketName: test-bucket-name
# (Optional) SNS topic ARN for job notifications and workflow alerts.
# Auto-resolved from project when projectName is set.
notificationTopicArn: arn:{{partition}}:sns:{{region}}:{{account}}:test-topic
# (Optional) Reusable job templates that can be inherited by job
# definitions via the template field. Template properties are
# deep-merged with job-specific overrides.
templates:
ExamplePythonTemplate:
# IAM role ARN for Glue job execution permissions.
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# Job command configuration defining script and runtime
# environment.
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# (Optional) Python version for job runtime. (enum: 2, 3)
pythonVersion: '3'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/python/job.py
# Job description for documentation and management.
description: Example of a Glue Job using an inline script
# (Optional) Connection names for database and external system
# access.
connections:
- project:connections/connectionVpc
# (Optional) Default arguments passed to the job at runtime.
defaultArguments:
--job-bookmark-option: job-bookmark-enable
# (Optional) Execution properties including maximum concurrent
# runs.
executionProperty:
maxConcurrentRuns: 1
# (Optional) Glue runtime version for the job.
glueVersion: '2.0'
# (Optional) Maximum DPU capacity for the job.
# Note: Use maxCapacity OR workerType+numberOfWorkers, not both.
maxCapacity: 1
# (Optional) Maximum retry count before job failure.
maxRetries: 3
# (Optional) Notification settings for job monitoring and
# alerting.
notificationProperty:
# After a job run starts, minutes to wait before sending a
# delay notification.
notifyDelayAfter: 1
# (Optional) Job timeout in minutes.
timeout: 60
ExampleScalaTemplate:
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# (Optional) Default arguments passed to the job at runtime.
defaultArguments:
--job-language: scala
# (Optional) Glue runtime version for the job.
glueVersion: '5.0'
# Map of job names to Glue job definitions for ETL processing and
# data transformation.
jobs:
PythonJobOne:
# (Optional) Template name for configuration inheritance.
template: 'ExamplePythonTemplate'
defaultArguments:
--Input: s3://some-bucket/some-location1
# (Optional) Number of capacity units allocated to the job.
allocatedCapacity: 2
# (Optional) Continuous logging configuration for real-time
# monitoring.
continuousLogging:
# CloudWatch log group retention in days. Allowed:
# 1,3,5,7,14,30,60,90,120,150,180,365,400,545,731,1827,3653,0.
logGroupRetentionDays: 3
PythonJobTwo:
template: 'ExamplePythonTemplate'
defaultArguments:
--Input: s3://some-bucket/some-location2
--enable-spark-ui: 'true'
--spark-event-logs-path: s3://some-bucket/spark-event-logs-path/JobTwo/
allocatedCapacity: 20
# (Optional) Relative paths to additional Python scripts for
# the job.
additionalScripts:
- ./src/glue/python/helper_etl.py
- ./src/glue/python/utils/core.py
# (Optional) Relative paths to additional files for the job.
additionalFiles:
- ./src/glue/scala/extra_file.txt
ScalaJobOne:
template: 'ExampleScalaTemplate'
description: testing
defaultArguments:
--class: some.java.package.App
allocatedCapacity: 2
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/scala/App.scala
# (Optional) Relative paths to additional files for the job.
additionalFiles:
- ./src/glue/scala/extra_file.txt
# (Optional) Relative paths to additional JAR files for the job.
additionalJars:
- ./src/glue/scala/lib/extra.jar
Worker Type Configuration
Uses workerType + numberOfWorkers instead of maxCapacity for explicit control over Glue worker sizing (Standard, G.1X, or G.2X). Choose this variant when you need predictable worker allocation instead of maxCapacity-based auto-scaling.
# Contents available via above link
# Sample config for the DataOps Job module - workerType variant.
# Exercises the workerType + numberOfWorkers path which is mutually
# exclusive with maxCapacity. Covers all three workerType enum values.
# (Optional) DataOps project name for job resource autowiring
# (databases, roles, security).
projectName: dataops-project-test
# Map of job names to Glue job definitions for ETL processing and
# data transformation.
jobs:
# Job using Standard worker type.
StandardWorkerJob:
# IAM role ARN for Glue job execution permissions.
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# Job description for documentation and management.
description: Glue ETL job with Standard worker type
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# (Optional) Python version for job runtime. (enum: 2, 3)
pythonVersion: '3'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/python/job.py
# (Optional) Glue runtime version for the job.
glueVersion: '2.0'
# (Optional) Worker type. (enum: Standard, G.1X, G.2X)
# Note: Use workerType+numberOfWorkers OR maxCapacity, not both.
workerType: Standard
# (Optional) Number of workers for parallel processing.
numberOfWorkers: 2
# Job using G.1X worker type.
G1XWorkerJob:
# IAM role ARN for Glue job execution permissions.
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# Job description for documentation and management.
description: Glue ETL job with G.1X worker type
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# (Optional) Python version for job runtime. (enum: 2, 3)
pythonVersion: '3'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/python/job.py
# (Optional) Glue runtime version for the job.
glueVersion: '3.0'
# (Optional) Worker type. (enum: Standard, G.1X, G.2X)
workerType: G.1X
# (Optional) Number of workers for parallel processing.
numberOfWorkers: 4
# Job using G.2X worker type.
G2XWorkerJob:
# IAM role ARN for Glue job execution permissions.
# Often created by the Roles module.
# Example SSM: ssm:/{{org}}/{{domain}}/<roles_module_name>/role/<role_name>/arn
executionRoleArn: some-arn
# Job description for documentation and management.
description: Glue ETL job with G.2X worker type
command:
# Job type. (enum: glueetl, pythonshell)
name: 'glueetl'
# (Optional) Python version for job runtime. (enum: 2, 3)
pythonVersion: '3'
# Relative path to the Glue script for job execution.
scriptLocation: ./src/glue/python/job.py
# (Optional) Glue runtime version for the job.
glueVersion: '4.0'
# (Optional) Worker type. (enum: Standard, G.1X, G.2X)
workerType: G.2X
# (Optional) Number of workers for parallel processing.
numberOfWorkers: 8