Basic Data Lake
This basic S3 Data Lake sample illustrates how to create an S3 data lake on AWS. Access to the data lake may be granted to IAM and federated principals, and is controlled on a coarse-grained basis only (using S3 bucket policies).
This architecture may be suitable when:
- Data is primarily unstructured and will not be consumed via Athena.
- User access to the data lake does not need to be governed by fine-grained access controls.
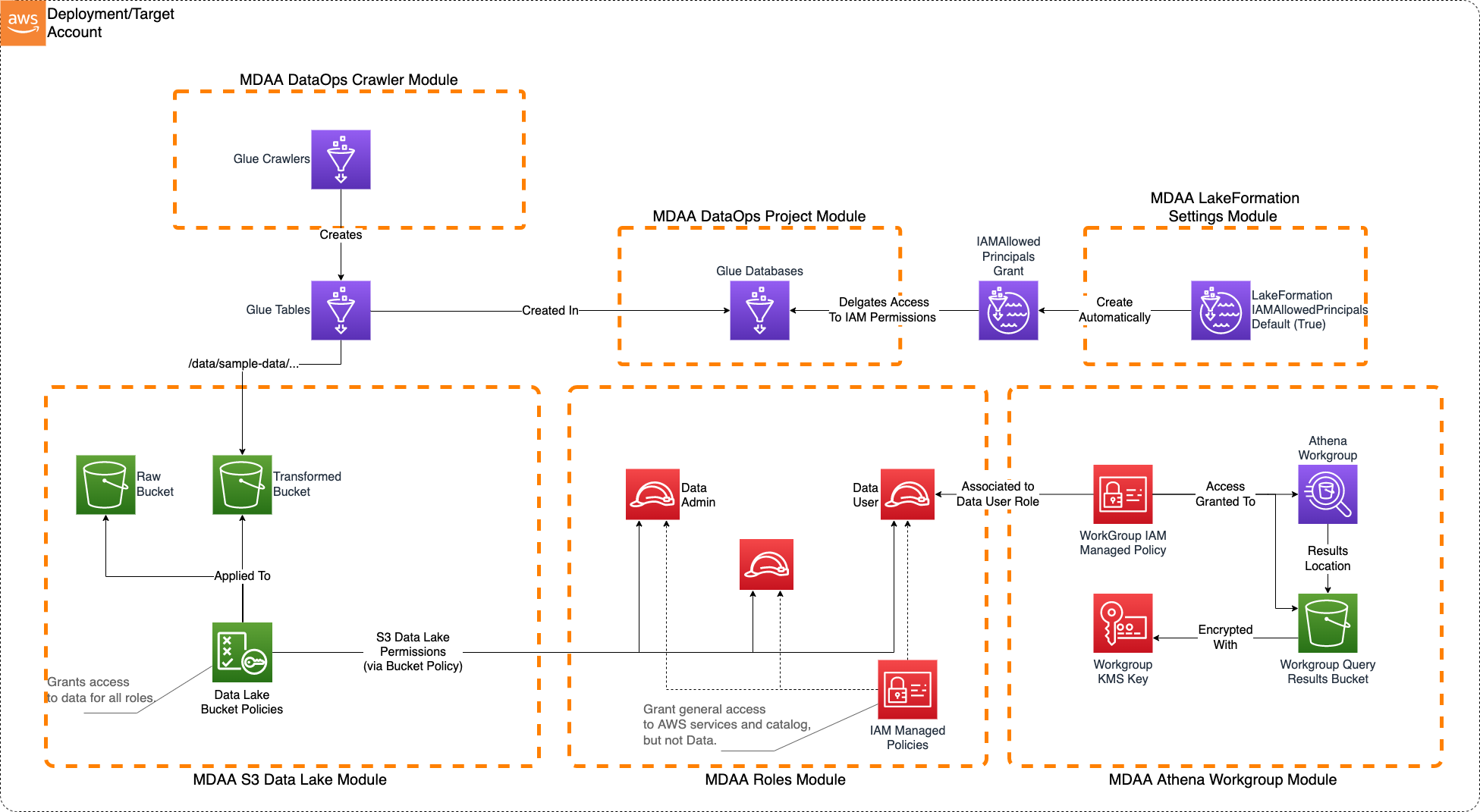
Deployment Instructions
The following instructions assume you have CDK bootstrapped your target account, and that the MDAA source repo is cloned locally. More predeployment info and procedures are available in PREDEPLOYMENT.
-
Deploy sample configurations into the specified directory structure (or obtain from the MDAA repo under
starter_kits/basic_datalake). -
Edit the
mdaa.yamlto specify an organization name. This must be a globally unique name, as it is used in the naming of all deployed resources, some of which are globally named (such as S3 buckets). -
If required, edit the
mdaa.yamlto specifycontext:values specific to your environment. -
Ensure you are authenticated to your target AWS account.
-
Optionally, run
<path_to_mdaa_repo>/bin/mdaa lsfrom the directory containingmdaa.yamlto understand what stacks will be deployed. -
Optionally, run
<path_to_mdaa_repo>/bin/mdaa synthfrom the directory containingmdaa.yamland review the produced templates. -
Run
<path_to_mdaa_repo>/bin/mdaa deployfrom the directory containingmdaa.yamlto deploy all modules.
Additional MDAA deployment commands/procedures can be reviewed in DEPLOYMENT.
Configurations
The sample configurations for this architecture are provided below. They are also available under starter_kits/basic_datalake within the MDAA repo.
Config Directory Structure
basic_datalake
│ mdaa.yaml
│ tags.yaml
│ roles.yaml
│
└───datalake
│ └───datalake.yaml
│ └───lakeformation-settings.yaml
│ └───athena.yaml
│
└───dataops
│ └───project.yaml
│ └───crawler.yaml
|
└───governance
│ └───audit.yaml
│ └───audit-trail.yaml
│
mdaa.yaml
This configuration specifies the global, domain, env, and module configurations required to configure and deploy this sample architecture.
Note - Before deployment, populate the mdaa.yaml with appropriate organization and context values for your environment
# Contents available in mdaa.yaml
# All resources will be deployed to the default region specified in the environment or AWS configurations.
# Can optional specify a specific AWS Region Name.
region: default
# One or more tag files containing tags which will be applied to all deployed resources
tag_configs:
- ./tags.yaml
## Pre-Deployment Instructions
# TODO: Set an appropriate, unique organization name
# Failure to do so may result in global naming conflicts.
organization: <unique-org-name>
# Optional: IAM permissions boundary policy ARN.
# When specified, the managed policy is applied as a permissions boundary
# to all IAM roles across all stacks. Supports hierarchy — can be overridden
# at the domain or environment level to use a different boundary per scope.
# permissions_boundary_arn: arn:aws:iam::<account-id>:policy/<boundary-policy-name>
# One or more domains may be specified. Domain name will be incorporated by default naming implementation
# to prefix all resource names.
domains:
# The named of the domain. In this case, we are building a 'shared' domain.
shared:
# One or more environments may be specified, typically along the lines of 'dev', 'test', and/or 'prod'
environments:
# The environment name will be incorporated into resource name by the default naming implementation.
dev:
# The target deployment account can be specified per environment.
# If 'default' or not specified, the account configured in the environment will be assumed.
account: default
# The list of modules which will be deployed. A module points to a specific MDAA CDK App, and
# specifies a deployment configuration file if required.
modules:
# This module will create all the roles required for the datalake, as well as dataops layers running on top
roles: # The module name (ie 'roles') will be incorporated into resource name by the default naming implementation.
module_path: "@aws-mdaa/roles"
module_configs:
- ./roles.yaml
# This module will deploy the S3 data lake buckets.
# Coarse grained access may be granted directly to S3 for certain roles.
datalake:
module_path: "@aws-mdaa/datalake"
module_configs:
- ./datalake/datalake.yaml
# This module will ensure the Glue Catalog is KMS encrypted.
# NOTE: Account-level module — can only be deployed once per AWS account.
glue-catalog:
module_path: "@aws-mdaa/glue-catalog"
# This module will ensure that LakeFormation is configured to
# automatically generate IAMAllowedPrincipal grants on new databases and tables.
# This effectively delegates all Glue resource access controls
# to IAM.
# NOTE: Account-level module — can only be deployed once per AWS account.
lakeformation-settings:
module_path: "@aws-mdaa/lakeformation-settings"
module_configs:
- ./datalake/lakeformation-settings.yaml
# This module will create an Athena Workgroup which can be used to query
# the data lake.
athena:
module_path: "@aws-mdaa/athena-workgroup"
module_configs:
- ./datalake/athena.yaml
# This module will create a secure S3-based bucket for use as a Cloudtrail Inventory target.
audit:
module_path: "@aws-mdaa/audit"
module_configs:
- ./governance/audit.yaml
# This module will create a secure S3-based Audit Trail.
audit-trail:
module_path: "@aws-mdaa/audit-trail"
module_configs:
- ./governance/audit-trail.yaml
# The named of the domain. In this case, we are building a 'dataops' domain.
dataops:
# One or more environments may be specified, typically along the lines of 'dev', 'test', and/or 'prod'
environments:
# The environment name will be incorporated into resource name by the default naming implementation.
dev:
# The target deployment account can be specified per environment.
# If 'default' or not specified, the account configured in the environment will be assumed.
account: default
# The list of modules which will be deployed. A module points to a specific MDAA CDK App, and
# specifies a deployment configuration file if required.
modules:
# This module will create DataOps Project resources which can be shared
# across multiple
example-project:
module_path: "@aws-mdaa/dataops-project"
module_configs:
- ./dataops/project.yaml
example-crawler:
module_path: "@aws-mdaa/dataops-crawler"
module_configs:
- ./dataops/crawler.yaml
postdeploy:
command: "./dataops/create_table.sh {{org}} {{region}}"
exit_if_fail: true
example-data-quality:
module_path: "@aws-mdaa/dataops-data-quality"
module_configs:
- ./dataops/data-quality.yaml
tags.yaml
This configuration specifies the tags to be applied to all deployed resources.
roles.yaml
This configuration will be used by the MDAA Roles module to deploy IAM roles and Managed Policies required for this sample architecture.
# Contents available in roles.yaml
generatePolicies:
GlueJobPolicy:
policyDocument:
Statement:
- SID: GlueCloudwatch
Effect: Allow
Resource:
- "arn:{{partition}}:logs:{{region}}:{{account}}:log-group:/aws-glue/*"
Action:
- logs:CreateLogStream
- logs:AssociateKmsKey
- logs:CreateLogGroup
- logs:PutLogEvents
suppressions:
- id: "AwsSolutions-IAM5"
reason: "Glue log group name not known at deployment time."
DataAdminPolicy:
policyDocument:
Statement:
- Sid: BasicS3Access
Effect: Allow
Action:
- s3:ListAllMyBuckets
- s3:GetAccountPublicAccessBlock
- s3:GetBucketPublicAccessBlock
- s3:GetBucketPolicyStatus
- s3:GetBucketAcl
- s3:ListAccessPoints
- s3:GetBucketLocation
Resource: "*"
# Allows basic listing of KMS keys (required for up)
- Sid: BasicKMSAccess
Effect: Allow
Action:
- kms:ListAliases
Resource: "*"
suppressions:
- id: "AwsSolutions-IAM5"
reason: "These actions do not accept a resource or resource name not known at deployment time."
DataUserPolicy:
policyDocument:
Statement:
# This statement allows coarse-grained access to Glue catalog resources, but does not itself grant any access to data.
# Effective permissions are the intersection between IAM Glue Permissions and LF Grants. By establishing broad, coarse-grained permissions here,
# we are effectively concentrating effective permissions management in LF Grants.
- SID: GlueCoarseGrainedAccess
Effect: Allow
Resource:
- arn:{{partition}}:glue:{{region}}:{{account}}:catalog
- arn:{{partition}}:glue:{{region}}:{{account}}:database/*
- arn:{{partition}}:glue:{{region}}:{{account}}:table/*
Action:
- glue:GetDatabase
- glue:GetDatabases
- glue:GetCatalogImportStatus
- glue:GetTable
- glue:GetTables
- glue:GetPartition
- glue:GetPartitions
- glue:SearchTables
# This statement allows the basic listing of Athena workgroups
# Specific Athena accesses are granted by the Athena Workgroup module itself.
- SID: BasicAthenaAccess
Effect: Allow
Action:
- athena:ListWorkGroups
Resource: "*"
suppressions:
- id: "AwsSolutions-IAM5"
reason: "These actions do not accept a resource or resource name not known at deployment time."
# The list of roles which will be generated
generateRoles:
glue-etl:
trustedPrincipal: service:glue.amazonaws.com
# A list of AWS managed policies which will be added to the role
awsManagedPolicies:
- service-role/AWSGlueServiceRole
generatedPolicies:
- GlueJobPolicy
suppressions:
- id: "AwsSolutions-IAM4"
reason: "AWSGlueServiceRole approved for usage"
data-admin:
trustedPrincipal: this_account
additionalTrustedActions:
- "sts:TagSession"
awsManagedPolicies:
- AWSGlueConsoleFullAccess
generatedPolicies:
- DataUserPolicy
- DataAdminPolicy
suppressions:
- id: "AwsSolutions-IAM4"
reason: "AWSGlueConsoleFullAccess approved for usage"
data-user:
trustedPrincipal: this_account
generatedPolicies:
- DataUserPolicy
datalake/datalake.yaml
This configuration will be used by the MDAA S3 Data Lake module to deploy KMS Keys, S3 Buckets, and S3 Bucket Policies required for the basic Data Lake.
# Contents available in datalake/datalake.yaml
# A list of Logical Config Roles which can be referenced in Access Policies. Each Logical Config Role can have one or more IAM role Arns bound to it.
roles:
DataAdminRole:
- id: generated-role-id:data-admin
DataUserRole:
- id: generated-role-id:data-user
GlueETLRole:
- id: generated-role-id:glue-etl
# Definitions of access policies which grant access to S3 paths for specified Logical Config Roles.
# These Access Policies can then be applied to Data Lake buckets (they will be injected into the corresponding bucket policies.)
accessPolicies:
RootPolicy: # A friendly name for the access policy
rule:
# The S3 prefix path to which policy will be applied in the bucket policies.
prefix: /
# A list of Logical Config Roles which will be provided ReadWriteSuper access.
# ReadWriteSuper access allows reading, writing, and permanent data deletion.
ReadWriteSuperRoles:
- DataAdminRole
# This policy grants access for the Glue Crawler role to read/discover data from the data lake
# S3 buckets.
DataReadPolicy:
rule:
prefix: data/
ReadRoles:
- GlueETLRole
- DataUserRole
# The set of S3 buckets which will be created, and the access policies which will be applied.
buckets:
# A 'raw' bucket/zone
raw:
# The list of access policies which will be applied to the bucket
accessPolicies:
- RootPolicy
- DataReadPolicy
# A 'transformed' bucket/zone
transformed:
accessPolicies:
- RootPolicy
- DataReadPolicy
athena.yaml
This configuration will create a standalone Athena Workgroup which can be used to securely query the data lake via Glue resources. These Glue resources can be either manually created, created via MDAA DataOps Project module (Glue databases), or MDAA Crawler module (Glue tables).
# Contents available in datalake/athena.yaml
# Arns for IAM roles which will be provided to the Workgroup's resources (IE results bucket)
dataAdminRoles:
- id: generated-role-id:data-admin
# List of roles which will be provided usage access to the Workgroup Resources
athenaUserRoles:
- id: generated-role-id:data-user
dataops/project.yaml
This configuration will create a DataOps Project which can be used to support a wide variety of data ops activities. Specifically, this configuration will create a number of Glue Catalog databases and apply fine-grained access control to these using basic.
# Contents available in dataops/project.yaml
# Arns for IAM roles which will be provided to the projects's resources (IE bucket)
dataAdminRoles:
# This is an arn which will be resolved first to a role ID for inclusion in the bucket policy.
# Note that this resolution will require iam:GetRole against this role arn for the role executing CDK.
- id: ssm:/{{org}}/shared/generated-role/data-admin/id
# List of roles which will be used to execute dataops processes using project resources
projectExecutionRoles:
- id: ssm:/{{org}}/shared/generated-role/glue-etl/id
s3OutputKmsKeyArn: ssm:/{{org}}/shared/datalake/kms/arn
glueCatalogKmsKeyArn: ssm:/{{org}}/shared/glue-catalog/kms/arn
# List of Databases to create within the project.
databases:
# This database will be used to illustrate access grants
# using LakeFormation.
sample-database:
description: Test Database
# The data lake S3 bucket and prefix location where the database data is stored.
# Project execution roles will be granted access to create Glue tables
# which point to this location.
locationBucketName: ssm:/{{org}}/shared/datalake/bucket/transformed/name
locationPrefix: data/sample_data
dataops/crawler.yaml
This configuration will create Glue crawlers using the DataOps Crawler module.
# Contents available in dataops/crawler.yaml
# The name of the dataops project this crawler will be created within.
# The dataops project name is the MDAA module name for the project.
projectName: example-project
crawlers:
crawler1:
executionRoleArn: ssm:/{{org}}/shared/generated-role/glue-etl/arn
# (required) Reference back to the database name in the 'databases:' section of the crawler.yaml
databaseName: project:databaseName/sample-database
# (required) Description of the crawler
description: Example for a Crawler
# (required) At least one target definition. See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-glue-crawler-targets.html
targets:
# (at least one). S3 Target. See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-glue-crawler-s3target.html
s3Targets:
- path: s3://{{resolve:ssm:/{{org}}/shared/datalake/bucket/transformed/name}}/data/sample_data
governance/audit.yaml
This configuration will be used by the MDAA audit module to deploy the resources required to define a secure S3-based bucket on AWS for use as a CloudTrail or S3 Inventory target.
# Contents available in governance/audit.yaml
# Roles which will be provided read access to the audit logs via bucket policy.
# Roles within the target account may be referenced by id, arn, and/or name.
readRoles:
- id: generated-role-id:data-admin
governance/audit-trail.yaml
This configuration will be used by the MDAA S3 Data Lake module to deploy the resources required to define a secure S3-based Audit Trail on AWS.
# Contents available in governance/audit-trail.yaml
trail:
# The name of the bucket to which audit events will be written
cloudTrailAuditBucketName: ssm:/{{org}}/shared/audit/bucket/name
# The Arn of the KMS CMK which will be used to encrypt audit logs
cloudTrailAuditKmsKeyArn: ssm:/{{org}}/shared/audit/kms/arn
# Optionally include control plane events in trail
includeManagementEvents: true
Usage Instructions
Once the MDAA deployment is complete, follow these steps to interact with the data lake.
-
Check the
DATASETS.mdfile in the same directory to create a sample_data folder -
Assume the
data-adminrole created by the MDAA deployment. This role is configured with AssumeRole trust to the local account by default. Note that this role is the only role configured with write access to the data lake. All other roles (including existing administrator roles in the account) will be denied write access. -
Upload the
./sample_datafolder and contents to<transformed_bucket>/data/sample_data -
In the Glue Console, trigger/run the Glue Crawler. Once successful, view the Crawler's CloudWatch logs to observe that two tables were created.
-
Assume the
data-userrole created by the MDAA deployment. This role is configured with AssumeRole trust to the local account by default. -
In the Athena Query Editor, select the MDAA-deployed Workgroup from the drop down list.
-
The two tables created by the crawler should be available for query under the MDAA-created Database.